在处理文档格式转换时,尤其是将PDF文件转换成Word文档,用户经常会遇到各种问题,其中乱码现象尤为常见,乱码不仅影响阅读体验,还可能导致重要信息的丢失或误解,本文旨在探讨PDF转换成Word后出现乱码的原因、解决方案及预防措施,帮助用户有效应对这一挑战。
乱码成因分析
1、编码不匹配:PDF文件可能使用了与Word默认设置不同的字符编码(如UTF-8, GBK等),导致转换过程中字符无法正确映射。

2、字体缺失:PDF中使用的特定字体在Word中未安装或不支持,使得文字显示为乱码或方块。
3、特殊格式与元素:PDF内嵌的特殊符号、图表、复杂布局或是加密保护,可能在转换过程中无法被准确解析和保留。
4、软件兼容性:不同PDF转Word工具的转换算法和技术实现差异,也会影响转换效果。
解决策略
1. 调整编码设置
手动检查:在Word中打开文档后,尝试更改文件的编码格式,点击“文件”>“信息”>“转换”,选择正确的编码方式重新加载文档。
专业软件辅助:使用如Adobe Acrobat Pro等高级PDF编辑工具,它们通常提供更精确的编码识别和转换选项。
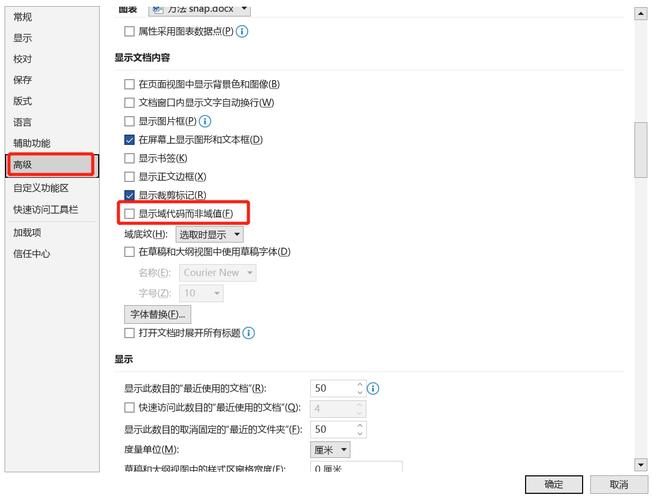
2. 字体嵌入与替换
字体安装:确保PDF中使用的所有字体都已安装在操作系统中,或者在Word中指定替代字体。
在线服务:利用在线字体识别服务,自动寻找并下载缺失的字体文件。
3. 优化转换工具选择
比较测试:尝试使用不同的PDF转Word工具,比如Adobe Acrobat DC, Nitro PDF to Word, Smallpdf等,对比其转换质量。
OCR技术应用:对于扫描版PDF,采用带有OCR(光学字符识别)功能的工具进行转换,以提高文本识别率。
4. 预处理PDF文件
:去除PDF中的复杂格式、图像或非标准元素,减少转换难度。
解密处理:如果PDF受密码保护,先使用合法途径解除限制再进行转换。
预防措施
源头控制:在创建PDF时就考虑后续编辑需求,尽量使用通用格式和标准字体。
备份原始文件:在进行任何转换操作前,保留原始PDF文件的副本,以防不测。
定期更新软件:保持PDF阅读器和转换工具的最新版本,以获得最佳兼容性和功能支持。
相关问答FAQs
Q1: 如果转换后的Word文档仍然显示乱码,应该怎么办?
A1: 首先确认是否已尝试所有推荐的解决方法,若问题依旧,考虑使用更高级的PDF处理软件进行深度分析,或联系原PDF文件的创建者获取更多信息,在某些情况下,可能需要手动校正文档内容。
Q2: 为什么有时即使使用了推荐的方法,转换效果还是不理想?
A2: 这可能是因为PDF文件本身存在难以克服的技术限制,如高度定制化的排版、特殊图形处理或是深层次的加密措施,除了上述方法外,还可以尝试分段转换、逐页处理或寻求专业的文档转换服务帮助。
PDF转换成Word后乱码的问题虽然常见,但通过合理的方法和工具选择,大多数情况下都能找到有效的解决之道,重要的是要了解乱码产生的根本原因,采取针对性措施,并在必要时寻求专业帮助。
到此,以上就是小编对于pdf转换成word后乱码怎么办的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位朋友在评论区讨论,给我留言。
内容摘自:https://news.huochengrm.cn/cydz/17136.html 13888888888
13888888888

 点击咨询
点击咨询 