在数字化办公日益普及的今天,将纸质文件转换为可编辑的Word文档已成为一项常见需求,这一过程不仅涉及图像扫描技术,还涵盖了光学字符识别(OCR)技术的应用,使得转换后的文档保持高度的准确性和可编辑性,本文旨在详细介绍如何高效地将扫描文件转换成Word文档,并提供一些实用的技巧与建议,以帮助读者更好地完成这一任务。
选择合适的扫描设备与软件
1. 扫描设备的选择
普通文档:对于日常的文档转换,一般的办公室扫描仪或家用扫描仪已足够使用,这些设备通常能够提供足够的分辨率来保证文字清晰可辨。
特殊文档:如果需要转换的是书籍、杂志或其他装订材料,可能需要使用具有自动进纸功能的扫描仪,或者考虑使用专业的书刊扫描仪。
2. 扫描软件的选择
自带软件:大多数扫描仪都会附带基本的扫描软件,可以满足简单的扫描需求。
第三方软件:对于更高级的需求,如批量处理、自动校正等,可以选择Adobe Acrobat、ABBYY FineReader、Readiris等专业软件。
扫描文件的准备与设置
1. 文件准备
确保文件平整无折痕,避免扫描时产生阴影或模糊。
如果文件有破损或污渍,尽量修复或清洁后再进行扫描。
2. 扫描设置
分辨率:一般设置为300dpi(每英寸点数),这个分辨率既能保证文字清晰,又不会过大导致文件体积膨胀。
颜色模式:对于黑白文档,选择灰度或黑白模式即可;彩色文档则选择彩色模式。
保存格式:推荐保存为PDF格式,因为PDF易于传输且兼容性好,后续可以通过OCR技术转换为Word。
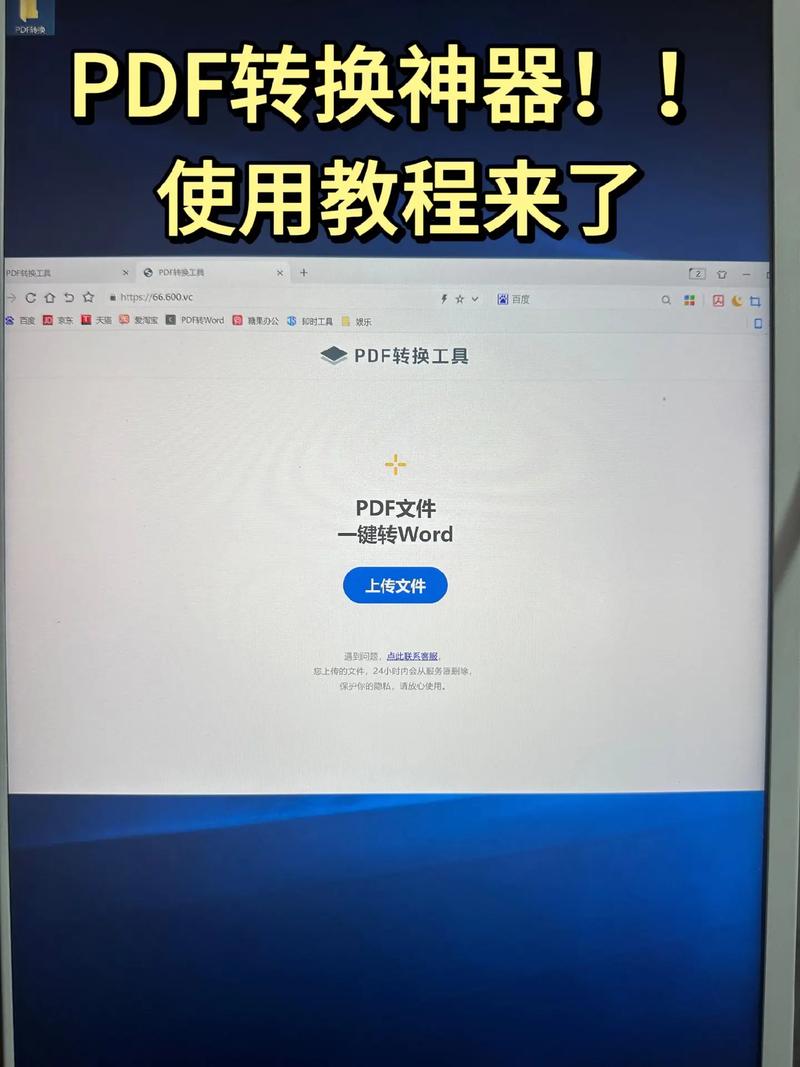
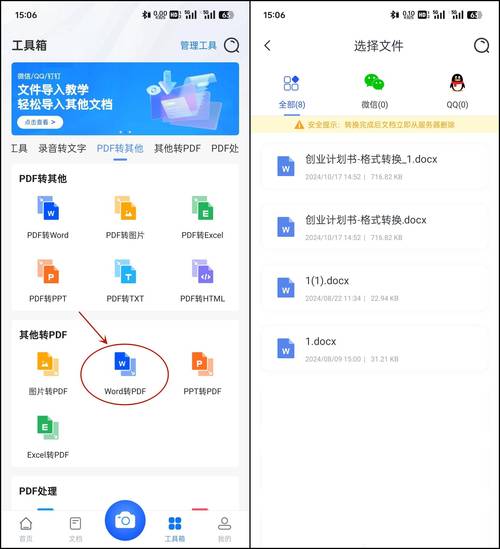
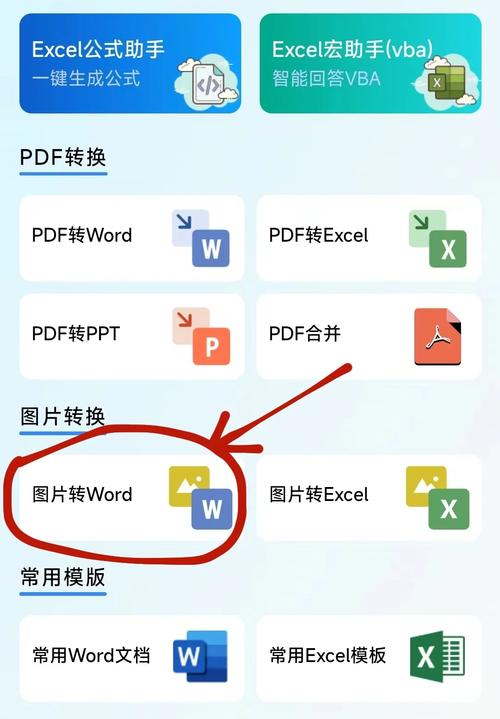
利用OCR技术转换扫描文件
1. OCR软件的选择
免费选项:Tesseract是一个开源的OCR引擎,虽然功能强大但配置相对复杂。
付费选项:ABBYY FineReader、Readiris等提供了更为直观易用的用户界面和更高的识别准确率。
2. OCR转换步骤
导入PDF:将扫描得到的PDF文件导入到OCR软件中。
识别语言:选择正确的识别语言,这对于提高识别准确率至关重要。
开始识别:点击“识别”或类似按钮,软件会自动处理并尝试将图像中的文字转换为可编辑文本。
校对与编辑:尽管现代OCR技术已经相当成熟,但仍可能存在少量错误,因此手动校对是必不可少的步骤。
优化与导出Word文档
1. 格式调整
根据需要调整段落、字体、行距等,以确保文档的专业性和可读性。
插入页眉页脚、目录等元素,使文档更加完整。
2. 导出Word文档
在OCR软件中完成所有编辑后,选择“另存为”或“导出”功能,将文件保存为Word格式(.docx)。
检查转换后的Word文档,确保所有内容都已正确转换且排版无误。
常见问题解答(FAQs)
Q1: OCR转换后的Word文档为什么会出现乱码?
A1: 乱码通常是由于OCR软件未能正确识别文字导致的,可能的原因包括扫描质量不佳(如分辨率过低、对比度不足)、选择了错误的识别语言、或者原始文档本身就存在难以识别的字体或格式,解决这个问题可以尝试提高扫描分辨率、调整OCR设置中的识别语言,或者在转换前对扫描件进行预处理(如增强对比度)。
Q2: 如何提高OCR转换的准确率?
A2: 提高OCR转换准确率可以从以下几个方面入手:确保扫描质量高,包括适当的分辨率和良好的对比度;正确选择识别语言,特别是对于包含多种语言的文档;利用OCR软件的高级功能,如自定义字典、学习模式等,来训练软件更好地识别特定类型的文本;转换后务必进行人工校对,修正任何识别错误。
通过上述步骤和建议,您可以有效地将扫描文件转换为高质量的Word文档,从而提高工作效率并减少重复劳动,随着技术的不断进步,未来的OCR工具将会更加智能化,为用户提供更加便捷高效的文档转换体验。
以上就是关于“扫描文件怎么转换成word”的问题,朋友们可以点击主页了解更多内容,希望可以够帮助大家!
内容摘自:https://news.huochengrm.cn/cygs/12876.html 13888888888
13888888888

 点击咨询
点击咨询 