在数字化办公环境中,将扫描文件转换成Word文档是一项常见且重要的任务,这不仅能够提高工作效率,还能便于后续的编辑和处理,本文将详细介绍几种有效的方法来实现这一目标,包括使用OCR(光学字符识别)技术和各种软件工具。
使用在线OCR工具
1. OnlineOCR.net
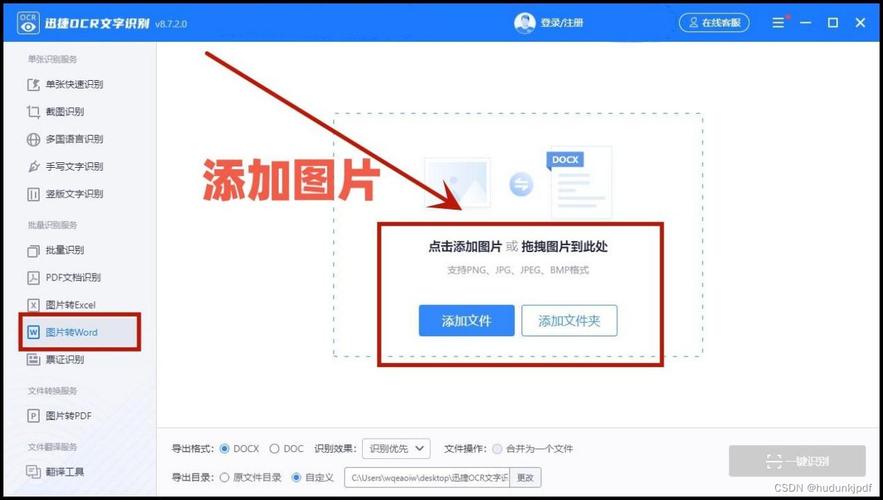
OnlineOCR.net是一个免费的在线OCR服务,支持多种语言的文本识别,以下是使用步骤:
上传文件:访问OnlineOCR.net网站,点击“选择文件”按钮上传需要转换的扫描文件。
选择语言:在页面上选择适当的语言(如简体中文、繁体中文或英文)。
开始转换:点击“Convert”按钮,等待系统完成转换。
下载结果:转换完成后,点击“Download DOC”按钮下载Word文档。
2. Free Online OCR
Free Online OCR同样提供免费的在线OCR服务,支持批量文件转换,操作步骤如下:
上传文件:访问Free Online OCR网站,点击“选择文件”按钮上传扫描文件。
选择输出格式:在“Output format”下拉菜单中选择“DOC”作为输出格式。
开始转换:点击“Convert”按钮,等待系统完成转换。
下载结果:转换完成后,点击“Download”按钮下载Word文档。
使用桌面软件
1. Adobe Acrobat DC
Adobe Acrobat DC是一款功能强大的PDF处理软件,内置OCR功能,可以将扫描文件转换为可编辑的Word文档,操作步骤如下:
打开文件:启动Adobe Acrobat DC,点击“File” > “Open”,选择需要转换的扫描文件。
启用OCR:在右侧工具栏中,点击“Enhance Scans”工具,然后选择“Recognize Text” > “In This File”。
导出为Word:OCR处理完成后,点击“File” > “Export To” > “Microsoft Word” > “Word Document”。
保存文件:选择保存位置并命名文件,点击“Save”按钮完成转换。
2. ABBYY FineReader
ABBYY FineReader是一款专业的OCR软件,适用于复杂文档的识别和转换,操作步骤如下:
打开文件:启动ABBYY FineReader,点击“File” > “Open”,选择需要转换的扫描文件。
选择OCR语言:在“Document Language”选项中选择适当的语言。
执行OCR:点击“Read”按钮,软件将自动进行OCR处理。
导出为Word:OCR处理完成后,点击“File” > “Save As”,选择Word格式(.docx)并保存文件。
使用手机应用
1. CamScanner
CamScanner是一款流行的手机扫描应用,支持OCR功能,以下是使用步骤:
安装应用:在App Store或Google Play商店下载并安装CamScanner。
扫描文件:打开CamScanner,使用手机摄像头扫描需要转换的文件。
启用OCR:扫描完成后,点击“Recognize Text”按钮,选择适当的语言。
导出为Word:OCR处理完成后,点击“Share”按钮,选择“Export to Word”选项,然后保存文件。
2. Office Lens
Office Lens是微软推出的一款免费扫描应用,支持OCR功能,操作步骤如下:
安装应用:在App Store或Google Play商店下载并安装Office Lens。
扫描文件:打开Office Lens,使用手机摄像头扫描需要转换的文件。
启用OCR:扫描完成后,点击“Convert”按钮,选择“Word (DOCX)”作为输出格式。
保存文件:选择保存位置并命名文件,点击“Save”按钮完成转换。
使用编程语言实现OCR
如果你有编程背景,可以使用Python结合Tesseract-OCR库来实现扫描文件到Word的转换,以下是一个简单的示例代码:
import pytesseract
from PIL import Image
import docx
配置Tesseract路径
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
打开图像文件
image = Image.open('scanned_file.jpg')
使用Tesseract进行OCR处理
text = pytesseract.image_to_string(image, lang='chi_sim+eng')
创建Word文档并写入识别的文本
doc = docx.Document()
doc.add_paragraph(text)
保存Word文档
doc.save('output.docx')表格对比不同方法
| 方法 | 优点 | 缺点 | 适用场景 |
| 在线OCR工具 | 免费、无需安装 | 可能受文件大小限制、隐私问题 | 偶尔使用、小文件 |
| 桌面软件 | 功能强大、精度高 | 需付费、占用存储空间 | 频繁使用、大文件 |
| 手机应用 | 便携、快速 | 精度相对较低、依赖网络 | 移动办公、紧急情况 |
| 编程实现 | 高度定制、灵活 | 需要编程知识、开发时间 | 特殊需求、自动化处理 |
常见问题解答(FAQs)
Q1: 如何提高OCR转换的准确性?
A1: 提高OCR转换准确性的方法包括:确保扫描文件清晰无模糊;调整OCR软件的语言设置以匹配文档语言;对于复杂布局的文档,手动调整OCR区域;如果可能,使用高分辨率的扫描仪进行扫描。
Q2: OCR转换后Word文档中的格式错乱怎么办?
A2: 如果OCR转换后Word文档中的格式错乱,可以尝试以下方法解决:使用Word的“查找和替换”功能修复常见的格式错误;手动调整段落和字体样式;如果格式问题严重,可能需要重新进行OCR转换或手动输入文本。
各位小伙伴们,我刚刚为大家分享了有关怎么把扫描文件转换成word的知识,希望对你们有所帮助。如果您还有其他相关问题需要解决,欢迎随时提出哦!
内容摘自:https://news.huochengrm.cn/cygs/12983.html 13888888888
13888888888

 点击咨询
点击咨询 