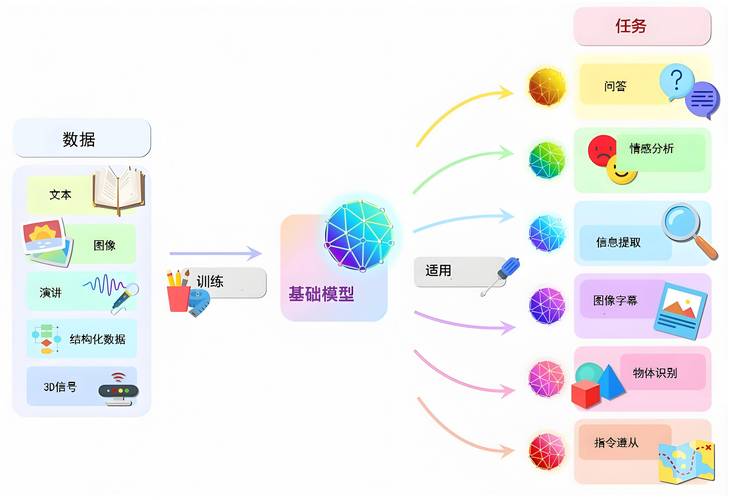
参数调优的本质:在约束中寻找平衡点
AI模型的参数分为可训练参数(如神经网络的权重)与超参数(如学习率、批量大小),前者由模型自动优化,后者需要人工干预,调参的核心目标在于:通过调整超参数,使模型在有限的计算资源下达到最佳泛化能力。
过高的学习率可能导致模型在训练初期震荡,无法收敛;而过低的学习率则会让训练效率大幅下降,这个过程如同调整显微镜焦距——需要耐心寻找最清晰的观测点。
必须关注的五大核心参数
学习率(Learning Rate)
决定模型每次更新权重的幅度,推荐采用动态调整策略:初始阶段设定较高值(如0.1),随着训练轮次增加逐步衰减(如每10轮降低50%)。批量大小(Batch Size)
影响内存占用与梯度稳定性,较小的批量(如32-128)通常更有利于模型泛化,但需配合梯度累积技术缓解显存压力。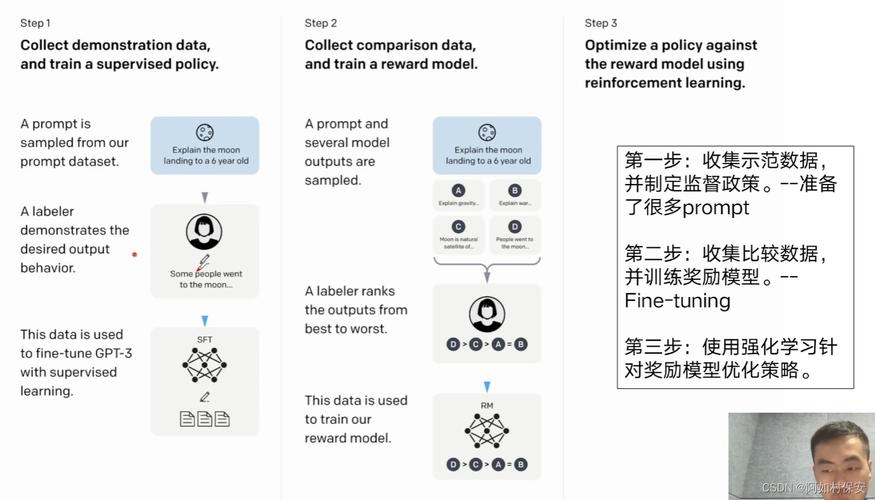
正则化系数(Regularization)
L1/L2正则化的强度参数,用于防止过拟合,建议从1e-4开始测试,观察验证集损失变化。丢弃率(Dropout Rate)
在0.2-0.5范围内调节,全连接层通常需要更高丢弃率,卷积层则可适当降低。
优化器参数
Adam优化器的β1(0.9)、β2(0.999)对收敛速度有显著影响,NLP任务中可尝试降低β2至0.98以加速训练。
参数调优的实战方法论
阶段1:基准测试
- 使用经典参数组合(如ResNet的初始学习率0.1)建立基线
- 记录训练损失、验证准确率、GPU内存占用量三项指标
阶段2:网格搜索与随机搜索
- 对2-3个关键参数进行网格搜索(如学习率×批量大小)
- 超过三个参数时改用随机搜索,采样50-100组配置
阶段3:自动化调参
- 采用贝叶斯优化工具(如Hyperopt)
- 设置早停机制(Early Stopping),当验证损失连续3轮未下降时终止训练
阶段4:敏感性分析
- 通过扰动实验观察参数变化对结果的影响程度
- 绘制学习率与准确率的曲线图,找到"甜蜜区"
避坑指南:高频错误与应对策略
盲目追求高精度指标
在测试集上过度调参会导致模型泛化能力下降,应始终保留独立验证集,并监控训练/验证损失的差距。忽视硬件限制
批量大小超过GPU显存容量时,可通过梯度累积模拟大批量效果,实际批量32时,累积4次等效于批量128。参数固化思维
不同任务的最佳参数存在显著差异,文本分类任务可能适用学习率3e-5,而目标检测任务常用1e-3作为起点。忽略随机种子影响
关键实验必须固定随机种子(如42),确保结果可复现。
案例解析:图像分类任务调参实录
某团队在CIFAR-10数据集训练ResNet-34时,初始验证准确率为72.3%,通过以下调整实现89.6%的提升:
- 学习率采用余弦退火策略,峰值设为0.05
- 加入CutMix数据增强,混合比例α=0.2
- 权重衰减调整为5e-4
- 批量大小从256降至64,并增加2步梯度累积
此过程耗时48小时,共尝试83组参数配置,最终选择验证损失最低的版本。
个人观点
参数调优是技术与艺术的结合,经验丰富的工程师往往能在5-10次迭代中找到较优解,这依赖于对模型架构的深刻理解与对数据分布的敏锐洞察,当前自动化调参工具虽能提升效率,但人工分析仍不可替代——就像自动驾驶汽车仍需人类设定目的地,建议开发者在初期投入时间手动调参,积累直觉认知,再逐步过渡到自动化流程。
随着神经架构搜索(NAS)技术的成熟,参数优化可能更多由AI自主完成,但在此之前,掌握参数调优的精髓,仍是每一位AI从业者的必修课。

 13888888888
13888888888

 点击咨询
点击咨询 