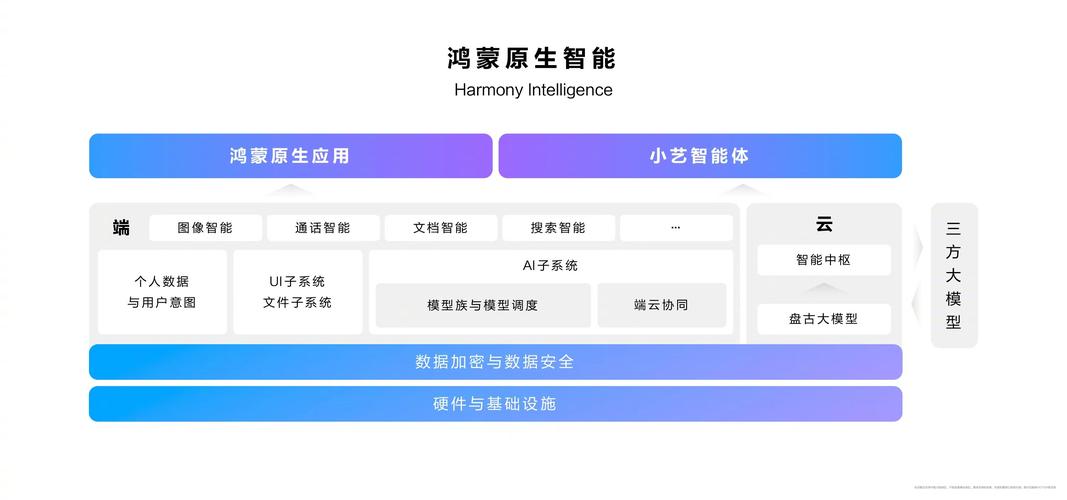
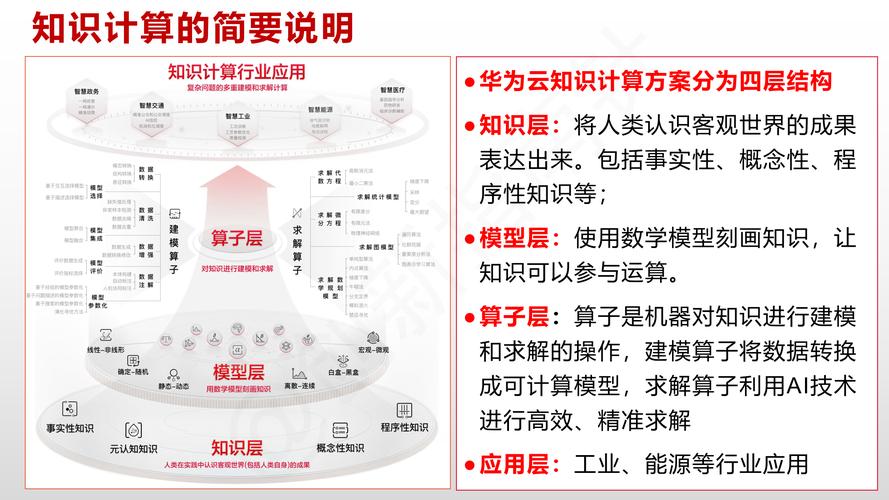
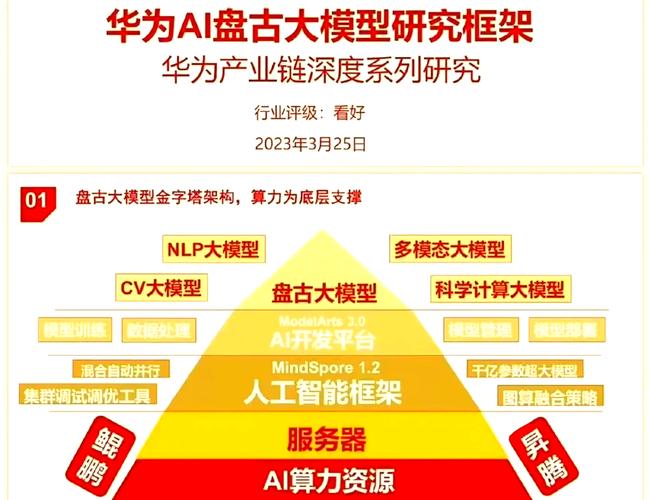
人工智能技术的快速发展,让华为AI模型成为开发者、企业用户甚至普通消费者关注的焦点,作为全球领先的科技企业,华为推出的AI模型不仅在性能上表现优异,其开放性和易用性也备受认可,本文将详细解析华为AI模型的配置方法,帮助用户快速上手并实现高效应用。
准备工作:明确需求与资源匹配
在开始配置华为AI模型前,需明确两个核心问题:
- 应用场景:模型将用于图像识别、自然语言处理,还是数据分析?不同场景需选择对应的模型架构。
- 硬件资源:华为AI模型支持云端部署(如华为云ModelArts平台)和本地部署(如Atlas系列硬件),若本地部署,需确保设备算力、内存满足最低要求。
以华为云ModelArts为例,用户需提前注册账号并完成实名认证,开通AI开发所需的基础服务(如对象存储OBS),本地部署则需检查设备是否安装兼容的驱动程序和框架(如MindSpore)。
环境配置:从开发到部署的全流程
步骤1:选择开发框架
华为AI模型的核心开发工具包括:
- MindSpore:华为自研的全场景AI计算框架,支持端边云协同。
- ModelArts:云端一站式开发平台,提供模型训练、部署及管理功能。
操作示例:
- 若使用ModelArts,登录后进入“开发环境”页面,创建Notebook实例(建议选择GPU加速规格);
- 在JupyterLab中安装MindSpore或PyTorch等依赖库;
- 通过代码调用华为预训练模型库(如Huawei Cloud Model Zoo),或上传自定义数据集。
步骤2:模型训练与调参
华为AI模型的训练需重点关注以下参数:
- 学习率(Learning Rate):初始值建议设为0.001,根据训练损失动态调整;
- 批次大小(Batch Size):需与显存容量匹配,避免内存溢出;
- 优化器选择:MindSpore推荐使用
Adam或Momentum。
注意事项:
- 使用混合精度训练(
model.train_network.to_float(mstype.float16))可提升效率; - 开启ModelArts的自动超参优化(HPO)功能,可自动搜索最佳参数组合。
步骤3:模型部署与推理
完成训练后,通过以下方式部署模型:
- 云端API部署:
- 在ModelArts中将模型打包为“.om”格式;
- 发布为在线服务,生成API调用地址和密钥。
- 边缘设备部署:
- 使用华为HiLens平台,将模型转换为适配昇腾芯片的格式;
- 通过SDK集成到摄像头、机器人等终端设备。
性能优化:提升模型效率的关键技巧
模型压缩技术
- 量化(Quantization):将32位浮点模型转换为8位整数,减少计算资源消耗;
- 剪枝(Pruning):移除神经网络中冗余的神经元,降低模型复杂度。
示例代码(MindSpore量化):
from mindspore.compression import QuantizationAwareTraining quantizer = QuantizationAwareTraining() model = quantizer.quantize(model)
多模型协同
针对复杂任务(如视频分析),可采用“主模型+辅助模型”架构:
- 主模型负责核心推理(如目标检测);
- 辅助模型处理次级任务(如行为识别),通过华为AI框架的并行计算功能提升整体效率。
常见问题与解决方案
训练过程中显存不足
- 降低批次大小;
- 启用梯度累积(Gradient Accumulation)。
模型推理速度慢
- 使用华为昇腾芯片的AI加速功能;
- 优化输入数据尺寸(如将图像缩放至固定分辨率)。
API调用延迟高
- 检查网络带宽;
- 启用ModelArts的负载均衡功能。
安全与合规性管理
华为AI模型内置多重安全机制:
- 数据加密:训练和推理过程中,数据全程通过TLS协议加密;
- 权限控制:通过IAM服务设置细粒度的访问权限;
- 合规认证:模型符合GDPR、中国个人信息保护法等法规要求。
个人观点
华为AI模型的优势在于其全栈技术能力——从底层芯片到开发框架,再到云端平台,形成了完整的闭环生态,对开发者而言,初期配置可能需投入一定时间熟悉工具链,但一旦掌握,其高效性和灵活性将显著降低长期运维成本,随着AI技术向行业纵深渗透,华为的“平台+生态”战略或将成为企业智能化转型的重要推手。

 13888888888
13888888888

 点击咨询
点击咨询 