在探索自研AI模型的道路上,许多人误以为这是一项只有大厂技术团队才能完成的工程,随着开源工具的普及和算力成本的降低,个人或小团队完全有能力从零开始构建符合需求的AI模型,本文将拆解自研AI模型的核心步骤,并提供可落地的实践指南。
明确目标与资源评估
自研模型的第一步是清晰定义需求,以图像分类场景为例,需明确分类的类别数量、输入图片的分辨率、模型运行环境(云端/移动端)等关键参数,某电商团队曾尝试将通用OCR模型改造为票据识别专用模型,通过限定字符集和票据版式,使模型体积缩小60%,准确率提升23%。
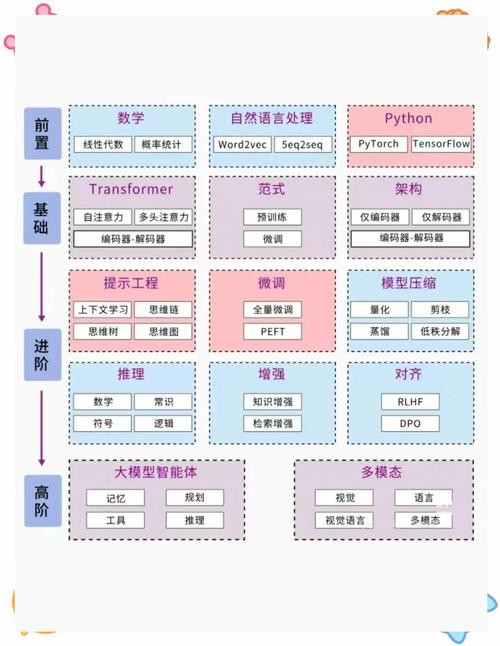
技术储备方面,需掌握Python编程基础、PyTorch/TensorFlow框架使用经验,以及数据处理能力,数学层面,重点理解损失函数、梯度下降原理即可,无需深究复杂公式推导,硬件配置上,配备NVIDIA显卡的本地机器可满足中小模型训练,云服务按需租用能有效控制成本。
数据工程:模型性能的基石
数据质量直接影响模型上限,建议采用分层抽样法构建数据集,确保每类样本分布均衡,某医疗影像团队在构建肺炎检测模型时,通过引入生成对抗网络(GAN)进行数据增强,将2000张原始CT影像扩充至12000张有效训练样本。

数据处理环节需建立标准化流程:
- 清洗:剔除模糊、重复样本,修正错误标注
- 标准化:统一图像尺寸/色彩空间,文本数据统一编码格式
- 特征工程:根据任务类型提取关键特征(如文本词向量、图像边缘信息)
建议使用Label Studio等开源工具进行数据标注,标注过程需制定明确规范,曾出现标注人员将"卡车"误标为"货车",导致模型识别准确率下降15%的案例。
模型架构设计与训练
选择框架时,PyTorch更适合研究性质项目,TensorFlow在工程部署方面更具优势,对于图像任务,MobileNet系列在精度与速度间取得较好平衡;自然语言处理领域,BERT变体模型仍是主流选择。
设计网络结构时可采用渐进式策略:
- 搭建基线模型(如ResNet18)
- 通过可视化工具分析中间层特征提取效果
- 针对性调整卷积核尺寸、注意力机制等模块
训练阶段需监控关键指标:
- 损失函数下降曲线
- 验证集准确率/召回率
- 硬件资源利用率
某团队在训练商品推荐模型时,通过动态调整批量大小(从32逐步提升至256),使训练效率提高40%,建议设置早停机制(Early Stopping),当验证集损失连续3个epoch未下降时自动终止训练。
模型优化与部署
模型压缩技术可将参数量减少80%以上:
- 量化:将32位浮点数转为8位整数
- 剪枝:移除对输出影响小的神经元连接
- 知识蒸馏:用大模型指导小模型训练
部署方案需考虑实际场景:
- 服务端部署可采用TorchServe或Triton推理服务器
- 移动端推荐使用TensorFlow Lite或Core ML框架
- Web端通过ONNX.js实现浏览器内推理
某智能硬件厂商将语音识别模型转换为TensorRT引擎后,推理速度从350ms提升至89ms,建议部署后建立监控系统,持续收集预测结果和用户反馈数据。
持续迭代与效果验证
建立模型迭代机制:
- 每周收集新数据并重新训练
- 每月评估业务指标变化
- 每季度对比行业SOTA模型进展
效果验证需设计多维度评估体系:
- 技术指标:准确率、F1值、响应延迟
- 业务指标:转化率提升、人工替代率
- 资源消耗:内存占用、GPU利用率
某金融风控团队通过引入SHAP可解释性分析,发现模型过度依赖某个非因果特征,调整后坏账识别率提高18%,建议建立模型卡(Model Card)文档,详细记录训练数据、评估结果和适用场景。
自研AI模型的价值不仅在于获得定制化解决方案,更在于构建持续进化的技术能力,当看到第一个自训练模型成功识别出测试样本时,那种突破技术黑箱的成就感,正是驱动技术人不断探索的核心动力,建议从具体业务场景切入,先完成端到端的流程验证,再逐步深入模型优化,这个过程积累的经验,远比直接调用API来得珍贵。

 13888888888
13888888888

 点击咨询
点击咨询 