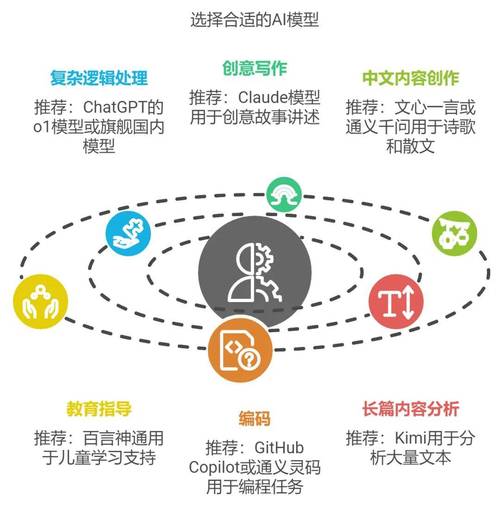
第一步:定位问题根源
AI模型的错误通常表现为预测不准确、结果偏差或运行崩溃,解决问题的第一步是明确错误类型:
- 数据问题:检查训练数据是否包含噪声、缺失值或标签错误,某医疗影像识别模型误诊率较高,可能是由于数据集中存在标注不清晰的病例图片。
- 算法设计缺陷:模型结构是否适合当前任务?比如在时间序列预测中,误用CNN而非RNN可能导致特征提取失效。
- 超参数设置不当:学习率过高可能导致模型震荡无法收敛;批次大小过小可能影响梯度更新稳定性。
- 环境兼容性:模型部署时,硬件加速库(如CUDA)的版本冲突或内存溢出也会引发错误。
案例参考:某电商推荐系统上线后点击率下降,最终发现是训练数据未过滤“虚假点击”行为,导致模型学习了噪声模式。

第二步:针对性优化策略
数据质量是核心
- 清洗与增强:通过统计方法(如Z-Score)识别异常数据;利用插值法填补缺失值;对类别不平衡问题,可采用SMOTE过采样或调整损失函数权重。
- 数据分布验证:确保训练集与测试集的数据分布一致,自动驾驶模型在晴天数据上训练,但测试时遇到雨天环境,需补充多场景数据。
算法调优方法论
- 模型简化:复杂模型未必更好,当错误率居高不下时,可尝试减少神经网络层数或改用轻量级架构(如MobileNet)。
- 正则化技术:添加Dropout层或L2正则化,防止过拟合,某金融风控模型曾因过拟合历史数据,对新用户行为预测失效,加入正则化后准确率提升12%。
- 交叉验证:采用K-Fold交叉验证评估模型泛化能力,避免单次划分数据导致的偶然性错误。
超参数自动化搜索
手动调整超参数效率低且依赖经验,工具如Optuna、Ray Tune可自动搜索最佳组合,某NLP模型通过贝叶斯优化将学习率从0.1调整至0.001后,训练损失下降30%。
第三步:部署后的持续监控
模型上线并非终点,动态监控能预防潜在风险:
- 输入数据监控:实时检测输入是否符合预期格式和范围,图像尺寸错误或文本包含乱码需触发告警。
- 性能衰减预警:通过A/B测试对比新旧模型效果,当推荐系统的转化率连续3天低于阈值时,自动回滚至上一稳定版本。
- 反馈闭环机制:收集用户对错误结果的标注,定期迭代模型,某客服机器人通过用户反馈修正了15%的语义理解错误。
第四步:建立容错与解释机制
- 容错设计:为关键系统设置备用模型,当主模型(如深度学习模型)失效时,备用规则引擎(如决策树)可临时接管,保障服务连续性。
- 可解释性工具:使用LIME、SHAP等工具分析错误原因,发现图像分类错误是由于模型过度关注背景而非主体对象,可针对性优化数据标注。
个人观点
AI模型的错误解决并非一劳永逸,而是需要将技术严谨性与工程思维结合,开发者需培养“数据敏感度”——从数据采集到模型迭代,每个环节都可能隐藏风险,避免陷入“盲目调参”的误区,理解算法原理比机械试错更重要,建立系统化的错误追踪文档,记录每次故障的原因与解决方案,能为团队积累宝贵的实战经验。

 13888888888
13888888888

 点击咨询
点击咨询 