了解常见的AI模型类型与格式
在下载模型前,需明确目标模型的类型及其对应格式,常见的模型类型包括预训练模型(如BERT、GPT)、图像分类模型(如ResNet、YOLO)以及生成模型(如Stable Diffusion),不同框架支持的模型格式各异:
- PyTorch:通常以
.pt或.pth文件保存,依赖配套代码加载。 - TensorFlow:使用
SavedModel格式或.h5文件,需搭配TensorFlow环境。 - Hugging Face Transformers:提供标准化的模型仓库,支持通过Python库直接调用。
- ONNX:跨平台格式,适用于多框架部署。
明确模型类型与格式后,可避免因兼容性问题导致无法使用。
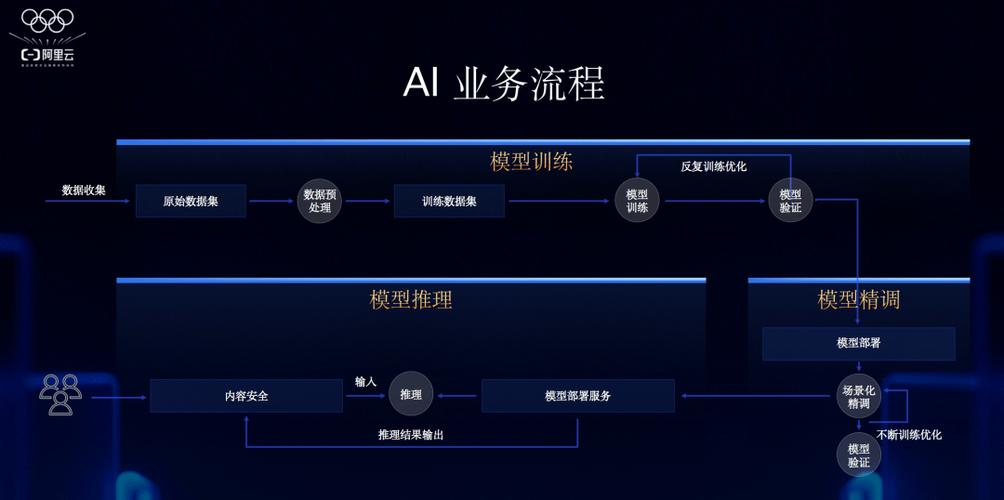
下载前的准备工作
确认硬件与软件环境
部分模型对算力要求较高(如大语言模型需GPU支持),需提前检查本地设备是否符合要求,安装对应框架(如PyTorch、TensorFlow)及依赖库,确保环境配置完整。阅读文档与许可证
开源模型通常附带使用协议(如MIT、Apache 2.0),商用场景需注意版权限制,文档中会注明模型的训练数据、适用场景及限制条件,避免误用。
选择可信来源
优先从官方渠道或知名社区平台获取模型,- Hugging Face Hub:涵盖自然语言处理、音频等多领域模型,支持在线试用。
- GitHub:开发者常在此发布代码与模型权重。
- TensorFlow Hub/PyTorch Hub:框架官方模型库,兼容性有保障。
- AI研习社、Kaggle:社区驱动的资源平台,用户可参考他人评价。
模型下载的常见方法
通过代码库直接下载
许多开源项目将模型与代码绑定,使用Hugging Face的transformers库时,可通过以下代码自动下载并加载模型:
from transformers import AutoModel, AutoTokenizer model_name = "bert-base-uncased" model = AutoModel.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)
此方式无需手动操作,但需注意网络稳定性。
从平台手动下载
部分平台提供模型文件的直接下载链接,以Hugging Face为例:
- 进入模型详情页,找到“Files and Versions”选项卡。
- 下载
pytorch_model.bin(权重文件)及config.json(配置文件)。 - 将文件放入本地项目目录,通过代码调用。
使用命令行工具
一些框架提供专用工具,TensorFlow用户可通过以下命令下载预训练模型:
tensorflow_datasets load mnist
注意事项与风险规避
验证模型完整性
下载后,检查文件哈希值是否与平台提供的一致,避免文件损坏或被篡改,Hugging Face会在模型页标注sha256校验码。警惕恶意代码
部分模型可能嵌入非常规依赖项(如第三方插件),需在隔离环境中测试后再部署到正式项目。关注模型更新
开发者可能修复漏洞或优化性能,定期查看版本更新日志,及时升级。合理分配存储空间
大模型(如GPT-3)的权重文件可能超过数十GB,下载前确保存储设备有足够空间。
模型下载后的使用建议
- 性能测试:在本地运行示例代码,确认模型能正常推理。
- 微调适配:若预训练效果不佳,可基于自有数据对模型微调。
- 社区互动:遇到问题时,可在GitHub Issues或论坛中寻求帮助,多数开源社区响应积极。

 13888888888
13888888888

 点击咨询
点击咨询 