语音训练的基本流程
语音模型的训练可以划分为三个核心阶段:数据准备、模型训练、部署优化。
-
数据采集与处理
语音数据的质量直接影响模型效果,建议采集覆盖不同性别、年龄、口音以及环境噪声的样本,针对中文语音模型,需包含普通话与常见方言(如粤语、川渝方言)的语音片段,数据清洗时,需去除无效音频(如静音段),并通过标准化采样率(如16kHz)统一格式。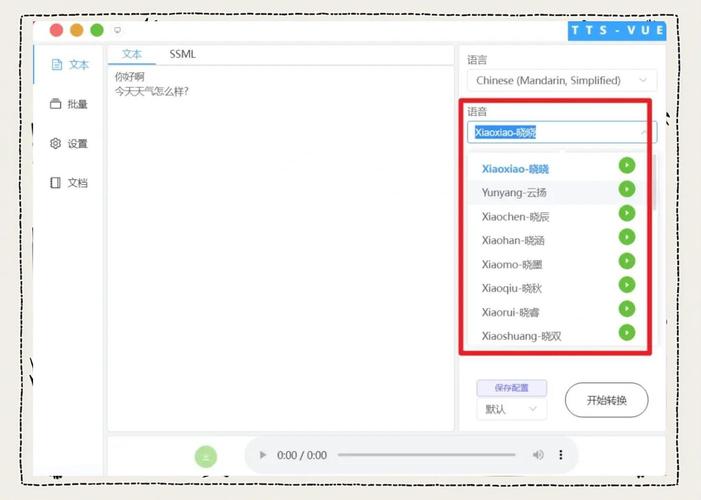
-
特征提取
声音信号需转化为机器可理解的数字特征,常用方法包括梅尔频谱(Mel Spectrogram)和MFCC(梅尔频率倒谱系数),梅尔频谱模拟人耳对声音频率的敏感度,能有效捕捉音调、节奏等关键信息。 -
模型训练
主流的语音模型架构包括循环神经网络(RNN)、Transformer以及端到端模型(如WaveNet),以Transformer为例,其自注意力机制能高效捕捉长距离语音依赖关系,训练时需设置合理的批次大小和学习率,避免过拟合。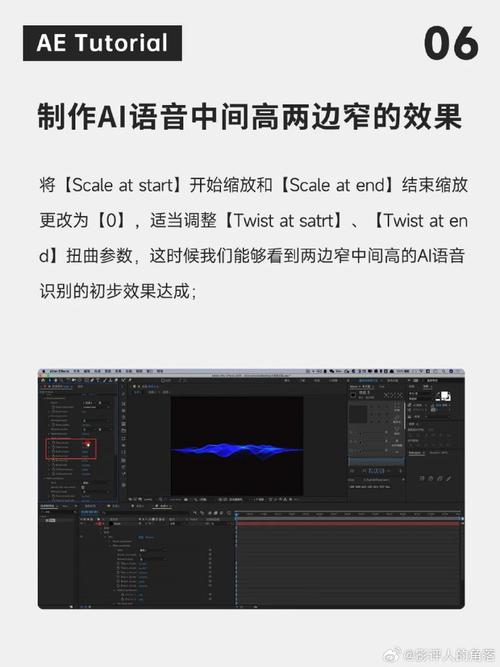
关键技术与实战技巧
数据增强:提升模型鲁棒性
在实际应用中,语音常伴随背景噪声,可通过添加随机噪声(如白噪声、餐厅环境音)、调整语速、改变音高来增强数据多样性,使用开源工具Librosa库可快速实现音频变速、变调处理。
迁移学习:节省训练成本
直接训练大型语音模型(如Whisper)需要高昂算力,推荐从预训练模型出发,通过微调(Fine-tuning)适配特定任务,使用普通话预训练模型,只需少量方言数据即可实现方言识别。

注意力机制:优化长语音处理
长语音片段易导致信息丢失,引入动态块注意力(Chunked Attention)可将音频切分为多个块,逐块处理后再拼接结果,实验表明,这种方法在30秒以上的长语音识别中准确率提升约12%。
典型应用场景
-
智能客服语音质检
通过训练定制化语音模型,可实时检测客服通话中的关键词(如“投诉”“退款”),并自动标记高风险对话,某金融公司采用此方案后,人工抽检工作量减少70%。 -
方言语音助手
针对方言用户,可收集区域语音数据训练专属模型,某地图APP的粤语导航功能,通过3万条粤语指令微调后,识别准确率从68%提升至92%。 -
实时语音转写
结合流式推理技术,模型可在用户说话时同步输出文字,关键技术包括流式编码器和动态解码,延迟需控制在300毫秒内以保证体验。
常见问题与解决方案
问题1:训练数据不足怎么办?
- 使用开源数据集(如AISHELL-1中文语音库)
- 采用数据合成技术:TTS生成语音后加入噪声
- 半监督学习:少量标注数据+大量未标注数据联合训练
问题2:模型推理速度慢?
- 量化压缩:将32位浮点参数转为8位整数
- 模型蒸馏:用大模型指导小模型训练
- 硬件加速:部署TensorRT或专用AI芯片
问题3:特定词汇识别率低?
- 在训练数据中针对性增加该词汇的多样本(不同语速、语调)
- 调整损失函数权重,提高关键字的识别优先级

 13888888888
13888888888

 点击咨询
点击咨询 