在数字化进程加速的当下,AI大模型的对接能力已成为企业技术升级的关键,无论是提升客户服务效率,还是优化内部管理流程,将AI大模型与现有系统无缝融合,都需要一套科学的方法论与实践经验,本文将从技术实现、策略选择到风险规避,系统化梳理对接过程中需关注的要点。
明确需求:从业务场景出发
对接AI大模型前,需优先梳理业务目标,电商平台可能需通过大模型实现智能客服的语义理解,而制造业企业可能更关注生产数据的预测分析,建议通过以下三步完成需求定义:
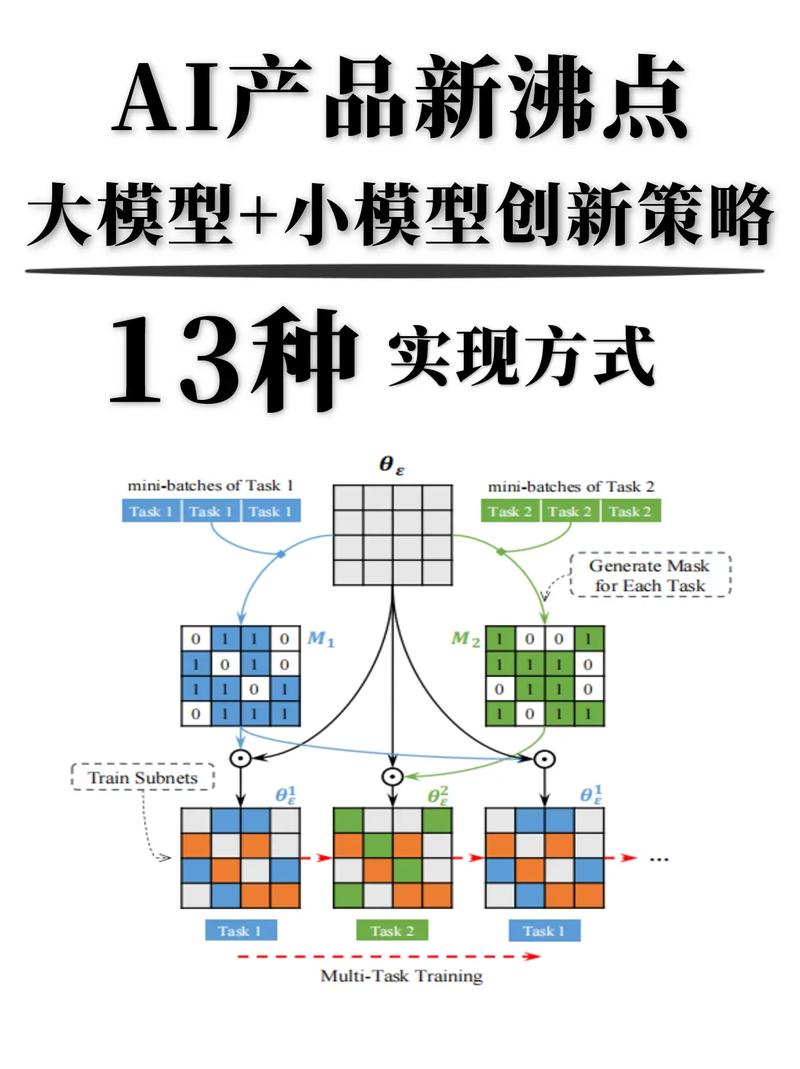
- 场景拆解:将业务问题转化为技术需求,提升用户咨询响应速度”可转化为“需支持每秒处理1000次自然语言请求”。
- 性能指标量化:明确响应时间、准确率、并发量等硬性指标,避免后期因性能不达标返工。
- 数据兼容性评估:检查现有系统的数据格式(如JSON、XML)、接口协议(RESTful、gRPC)是否与目标模型匹配。
某零售企业曾因未提前评估图像识别模型与POS系统的数据兼容性,导致对接后出现30%的订单信息解析错误,这一教训值得引以为鉴。
技术选型:平衡能力与成本
市面主流AI大模型各有侧重:GPT系列擅长文本生成,Stable Diffusion专注图像处理,而行业定制模型(如医疗领域的BioGPT)则在垂直领域表现更优,技术选型需重点考虑:
- API与本地部署的抉择:API调用成本低但依赖网络稳定性,金融类企业多选择私有化部署保障数据安全
- 模型微调必要性:通用模型准确率不足85%时,建议使用自有数据进行微调,某银行通过微调风险预测模型,将坏账识别准确率提升了19%
- 算力成本测算:使用工具(如TensorFlow Profiler)预估推理阶段的GPU消耗,避免预算超支
对接实施:构建稳健的技术链路
核心对接流程包含五个关键节点:
- 环境配置:部署CUDA工具包、PyTorch等基础框架,确保版本兼容
- 接口开发:遵循OpenAPI规范设计标准化接口,预留每秒20%的流量冗余
- 数据预处理:建立数据清洗管道,包括去噪、归一化、特征工程等环节
- 测试验证:实施A/B测试,对比新旧系统在相同负载下的表现差异
- 监控部署:集成Prometheus+Granfana监控体系,实时追踪API响应延迟、错误率等20+指标
某物流公司通过在预处理阶段增加地址标准化模块,使路径规划模型的预测准确率从78%提升至93%,验证了数据质量的关键作用。
风险控制:规避常见实施陷阱
根据Gartner调研,47%的AI项目失败源于对接阶段的管理疏漏,需特别注意:
- 安全防护:对输入输出数据进行正则表达式过滤,防范Prompt注入攻击
- 性能优化:采用模型量化(如FP16精度转换)可将推理速度提升2-3倍
- 合规审查:确保训练数据符合《个人信息保护法》要求,建立数据脱敏机制
- 容灾设计:设置备用模型实例,在主服务故障时10秒内自动切换
2023年某社交平台因未设置速率限制,导致大模型接口被恶意调用,单日产生超额费用37万元,这类事故可通过熔断机制避免。
持续迭代:建立反馈闭环
完成初步对接后,需构建持续优化机制:
- 通过埋点收集用户交互数据,识别高频错误类型
- 每月更新训练数据,防止模型性能衰减
- 监控行业最新论文(如arXiv每日更新),评估新技术适配性
- 每季度进行压力测试,验证系统扩容能力
智能制造企业施耐德电气即采用动态迭代策略,其设备故障预测模型每月更新训练数据,使预测准确率始终保持在92%以上。
站在技术演进的角度,AI大模型的对接已从单纯的技术集成,转变为驱动业务创新的核心引擎,当企业建立起标准化的对接流程体系,不仅能快速实现技术落地,更能在数字化转型中构建竞争壁垒,那些能系统性解决数据、算力、安全三角难题的团队,将在AI应用浪潮中掌握真正的主动权。

 13888888888
13888888888

 点击咨询
点击咨询 