理解基本概念与目标定位
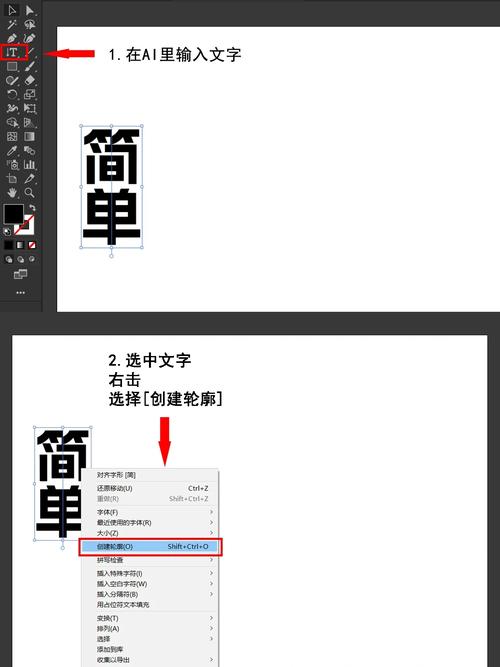
在开始创建AI文字模型之前,需明确其核心目标与应用场景,AI文字模型通常指通过机器学习技术生成或处理自然语言的系统,例如聊天机器人、文本摘要工具或内容创作助手,首先需要确定模型的用途:是生成创意内容、回答用户问题,还是完成特定领域的文本分析?明确目标后,才能选择合适的开发路径。
数据准备:构建高质量语料库
AI模型的性能高度依赖训练数据的质量,以下是数据准备的三个关键步骤:
- 数据收集
根据模型目标,从公开数据集(如Wikipedia、Common Crawl)、行业报告或用户生成内容中收集原始文本,若涉及垂直领域(如医疗、法律),需确保数据来源的专业性与权威性,符合E-A-T(专业性、权威性、可信度)原则。 - 数据清洗
去除重复、低质或无关内容,例如广告文本、乱码字符,针对中文场景,需统一繁简字、修正标点错误,对于生成类模型,建议保留完整段落以维持上下文逻辑。 - 数据标注
若需训练监督学习模型(如分类任务),需人工标注标签,情感分析需标记文本的正负面倾向,确保标注结果的一致性。
选择模型架构与开发工具
当前主流方案包括预训练模型微调与从零构建模型两种:
- 预训练模型微调(推荐)
使用如GPT-3、BERT、T5等开源预训练模型,通过少量领域数据调整参数,优势在于节省算力成本,快速实现基础功能,Hugging Face平台提供丰富的模型库和接口文档,适合中小规模团队。 - 从零构建模型
需设计神经网络架构(如LSTM、Transformer),并利用TensorFlow、PyTorch等框架实现,此方案适合研究性质项目或高度定制化需求,但对算力与技术要求较高。
开发工具选择建议:

- 编程语言:Python(主流生态支持)
- 深度学习框架:PyTorch(灵活性强)、TensorFlow(工业部署便捷)
- 云平台:Google Colab(免费GPU资源)、AWS SageMaker(企业级支持)
模型训练与调优策略
训练阶段需关注以下核心参数与技巧:
- 超参数设置
- 学习率(Learning Rate):初始值建议设为1e-5至1e-3,结合学习率衰减策略。
- 批次大小(Batch Size):根据GPU内存调整,通常设为16-64。
- 训练轮次(Epochs):通过早停法(Early Stopping)防止过拟合。
- 损失函数选择
文本生成任务常用交叉熵损失(Cross-Entropy Loss),分类任务可选择Focal Loss应对类别不平衡问题。 - 评估指标优化
除准确率(Accuracy)外,需结合BLEU(生成质量)、F1 Score(分类均衡性)等指标综合评估。
调优技巧:
- 引入注意力机制(Attention)提升长文本处理能力
- 采用知识蒸馏(Knowledge Distillation)压缩模型体积
- 使用对抗训练(Adversarial Training)增强鲁棒性
部署与持续迭代
模型训练完成后,需通过以下步骤投入实际应用:
- 性能测试
使用独立测试集验证泛化能力,避免数据泄露导致的虚假高精度。 - 部署方案
- 本地部署:通过Flask或FastAPI封装API接口
- 云端服务:使用AWS Lambda或阿里云函数计算实现弹性扩展
- 监控与更新
建立日志系统跟踪用户交互数据,定期用新数据微调模型,聊天机器人需根据用户反馈修正错误回答模式。
合规与伦理考量
AI文字模型的应用需符合法律法规与道德规范:
- 版权风险:确保训练数据不侵犯第三方知识产权
- 偏见控制:检测并修正模型输出的性别、种族歧视倾向
- 透明度声明:向用户明确说明AI生成内容的属性
个人观点
AI文字模型的开发并非单纯的技术堆砌,而是对需求理解、数据质量与工程落地的综合考验,中小团队可从轻量级预训练模型切入,逐步积累领域数据与调优经验,随着多模态技术与低代码平台的发展,AI文字模型的创建门槛将进一步降低,但核心竞争力的构建仍依赖于对垂直场景的深度洞察。

 13888888888
13888888888

 点击咨询
点击咨询 