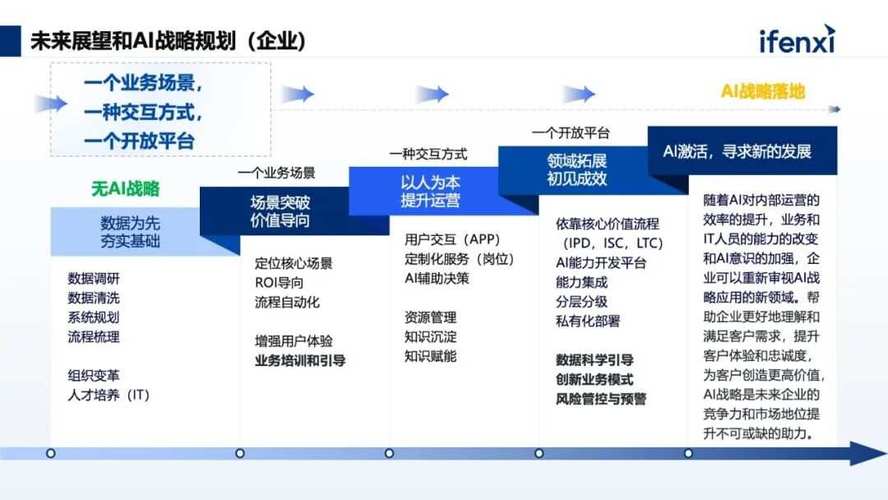
人工智能技术正逐步渗透到生活的方方面面,从智能客服到医疗诊断,从自动驾驶到个性化推荐,AI模型的构建能力已成为个人与企业的核心竞争力,如何从零开始构建一个AI模型?本文将拆解关键步骤,提供可落地的实操指南,帮助读者跨越理论与实践的鸿沟。
第一步:明确目标与场景定义
构建AI模型的第一步并非直接处理数据或编写代码,而是清晰定义模型的应用场景,图像识别模型需明确识别对象类型(如人脸、车辆)、使用场景(实时监控或离线分析),金融风控模型需确定评估维度(信用评分、欺诈检测)、数据来源(交易记录、用户行为)。
核心问题包括:

- 模型解决的具体问题是什么?
- 输入数据的形式与规模如何?
- 期望的输出结果是什么?
这一步的精准定义直接影响后续数据收集与模型选型,自然语言处理任务若需要实时对话能力,则需优先选择轻量化模型架构。
第二步:数据收集与预处理
数据是AI模型的“燃料”,其质量直接决定模型的上限。
数据来源的典型途径:
- 公开数据集(如Kaggle、Google Dataset Search)
- 企业自有数据库(用户日志、业务系统记录)
- 传感器采集(物联网设备、摄像头)
- 第三方数据采购(需注意合规性)
数据清洗的关键操作:
- 缺失值处理:删除残缺样本或用均值、中位数填充
- 异常值检测:使用箱线图或3σ原则识别离群点
- 标准化与归一化:消除量纲差异(如Min-Max标准化)
- 特征工程:通过PCA降维或构造组合特征提升信息密度
案例:电商推荐系统中,用户点击数据需剔除机器人流量,将浏览时长转化为时间区间特征,并通过独热编码处理商品类别。
第三步:模型选择与架构设计
模型选择需综合考虑计算资源、数据规模、任务复杂度三大因素。
常见模型类型对比:
| 任务类型 | 适用模型 | 优势场景 |
|------------------|----------------------------|----------------------|
| 图像分类 | CNN(ResNet、MobileNet) | 高精度、特征提取能力强 |
| 时序预测 | LSTM、Transformer | 长期依赖关系建模 |
| 文本生成 | GPT系列、BERT | 上下文理解能力优异 |
开源框架选型建议:
- 快速验证原型:Scikit-learn(传统机器学习)
- 深度学习开发:PyTorch(研究友好)、TensorFlow(生产部署)
- 边缘计算场景:ONNX Runtime(跨平台优化)
注意事项:医疗、金融等高敏感领域需优先选择可解释性强的模型(如决策树),避免“黑箱”带来的合规风险。
第四步:模型训练与调优
训练过程是反复迭代的系统工程,需平衡精度与效率。
关键调参策略:
- 学习率动态调整:使用余弦退火或OneCycle策略
- 正则化技术:Dropout层防止过拟合,L2正则化约束权重
- 早停机制(Early Stopping):监控验证集损失避免无效训练
性能评估方法:
- 分类任务:混淆矩阵、F1-Score、AUC-ROC曲线
- 回归任务:MAE、RMSE、R²系数
- 生成任务:BLEU、ROUGE、人工评测
进阶技巧:使用AutoML工具(如H2O.ai)自动搜索超参数组合,节省调参时间成本。
第五步:部署与持续优化
模型部署不是终点,而是运营的起点。
主流部署方案:
- 云端API:AWS SageMaker、Azure ML Studio
- 边缘设备:TensorFlow Lite、Core ML
- 混合架构:云端训练+边缘推理
模型监控指标:
- 实时吞吐量(QPS)
- 预测延迟(P99延迟)
- 数据漂移检测(PSI指数)
维护建议:建立A/B测试机制,当准确率下降5%以上时触发模型重训练流程,同时定期更新训练数据防止性能衰减。
伦理与风险控制
AI模型的构建需遵循技术伦理准则:
- 数据隐私保护:训练数据需进行匿名化处理,遵守GDPR等法规
- 偏见消除:检测不同性别、种族群体的预测结果公平性
- 失效保护机制:设置置信度阈值,低置信度预测转人工审核
2023年某国际零售企业曾因推荐算法歧视特定群体被起诉,最终付出900万美元和解金——这警示开发者必须将伦理设计嵌入建模全流程。

 13888888888
13888888888

 点击咨询
点击咨询 