人工智能技术发展迅速,大模型已成为推动行业变革的核心工具,许多企业和开发者希望构建自己的AI大模型,但面对复杂的流程和技术门槛,往往不知从何入手,本文将系统梳理构建AI大模型的关键步骤,帮助读者理清思路,找到适合自身需求的实现路径。
明确目标与场景需求
构建大模型的第一步是明确应用场景,医疗领域可能需要处理大量文本和影像数据,金融场景则需精准预测市场趋势,不同场景对模型的规模、训练数据和计算资源的要求差异巨大,如果目标是开发一个智能客服系统,模型需擅长自然语言理解和生成;若用于图像生成,则需侧重视觉特征提取能力,清晰的目标能帮助团队合理分配资源,避免盲目投入。
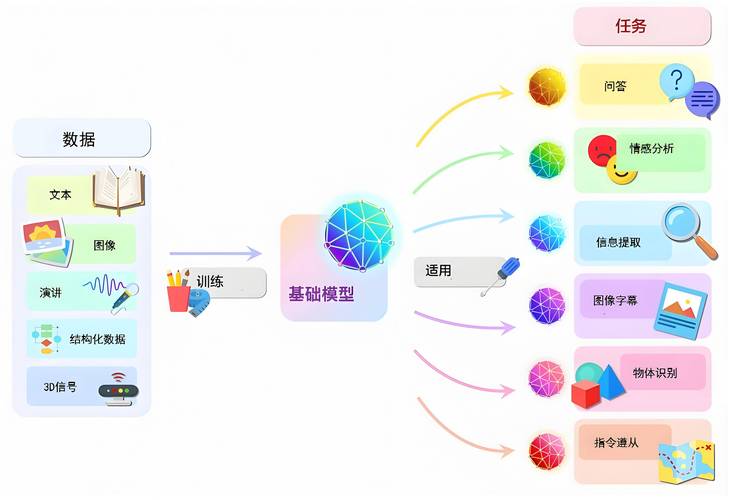
数据:大模型的根基
数据质量直接决定模型性能,以GPT-3为例,其训练数据涵盖书籍、论文、网页内容等超过45TB的文本,实际操作中,需完成三阶段工作:
- 数据采集:通过公开数据集(如Common Crawl)、行业数据库或自有数据源获取原始素材,需注意版权合规,尤其是商用场景。
- 数据清洗:去除重复、低质内容,训练对话模型时,需过滤含敏感信息或语法错误的语句,医疗数据则需专业人员进行脱敏处理。
- 数据标注:对非结构化数据添加标签,图像识别任务可能需要标注数百万张图片中的物体边界框,这个过程往往需要结合自动化工具与人工审核。
模型架构选择与优化
当前主流架构包括Transformer、MoE(混合专家)等,选择时需考虑:

- 计算效率:参数量超过千亿的模型需要分布式训练框架支持
- 任务适配性:BERT更适合文本理解类任务,GPT系列擅长生成式任务
- 可解释性:金融、法律等场景需模型具备决策过程的可追溯性
对于资源有限的团队,可采用迁移学习策略,基于开源的LLaMA模型进行微调,既能降低训练成本,又能获得专业领域的能力,某电商企业通过微调BERT模型,将商品推荐准确率提升了17%。
训练过程的工程挑战
训练百亿级参数的模型需要强大的算力支持,实际操作中常见的技术方案包括:
- 使用NVIDIA A100或H100 GPU集群,配合CUDA加速
- 采用混合精度训练(FP16/FP32结合)节省显存
- 部署ZeRO优化技术减少内存占用
监控系统必不可少,需实时跟踪损失函数变化、梯度爆炸/消失等情况,曾有多模态训练案例显示,当学习率设置为3e-5时,模型收敛速度比默认参数快40%。
部署与持续迭代
模型部署不是终点,实际应用中需建立反馈闭环:
- 通过A/B测试对比新旧模型效果
- 监控线上推理时延、吞吐量等性能指标
- 收集用户交互数据用于再训练
某智能客服系统上线后,团队发现用户在深夜的提问方式与白天存在差异,通过针对性补充训练数据,使夜间会话解决率提升了22%,模型压缩技术如知识蒸馏,可将大模型能力迁移至轻量级模型,更适合移动端部署。
伦理与安全考量
大模型可能产生偏见输出或隐私泄露风险,建议建立三道防线:
- 在数据预处理阶段嵌入去偏机制
- 推理环节设置内容过滤模块
- 建立人工审核通道处理敏感查询
教育领域有个典型案例:某语言学习App的AI助教最初会生成不恰当例句,后来通过强化学习引入价值观对齐机制,使不符合教育导向的输出降低了90%。
构建AI大模型如同建造智能工厂,既需要顶尖的设备(算力),也要有优质原材料(数据),更离不开经验丰富的工程师团队,当前技术迭代速度远超想象,三年前需要千卡集群训练半年的模型,现在通过算法优化可能只需十分之一资源,对于中小企业,与其追求参数规模,不如聚焦垂直场景,用精巧的模型设计解决具体问题,随着量子计算等新技术突破,大模型的构建门槛或将进一步降低,但核心逻辑不会改变——理解需求、夯实数据、持续创新,这才是驾驭AI浪潮的关键。

 13888888888
13888888888

 点击咨询
点击咨询 