建立对AI大模型的系统性认知
介入AI大模型的第一步是理解其核心逻辑,当前主流的大模型(如GPT系列、BERT、Stable Diffusion)本质是通过海量数据训练形成的复杂参数网络,能够完成文本生成、语义理解、图像创作等高阶任务,需明确两点核心差异:
- 模型类型:生成式模型(如ChatGPT)与判别式模型(如分类模型)的应用场景不同;
- 技术门槛:大模型的训练需要算力支持,但微调与应用开发可通过开源工具降低难度。
建议从行业报告(如Gartner技术趋势分析)及学术论文(arXiv平台)入手,了解不同模型的能力边界及适用领域。
明确目标:从需求反推技术路径
盲目追求技术热点可能导致资源浪费,介入AI大模型前需回答三个问题:
- 业务场景:是否需要提升效率(如自动化客服)?还是创造新服务(如AI内容生成)?
- 数据基础:是否有结构化数据支持模型训练或微调?
- 成本预算:是否具备算力资源(如GPU服务器)或可借助云服务(AWS、阿里云)?
某电商企业通过微调开源图像识别模型,将商品分类效率提升40%;而内容平台则借助API接入大模型,快速实现智能摘要生成功能。
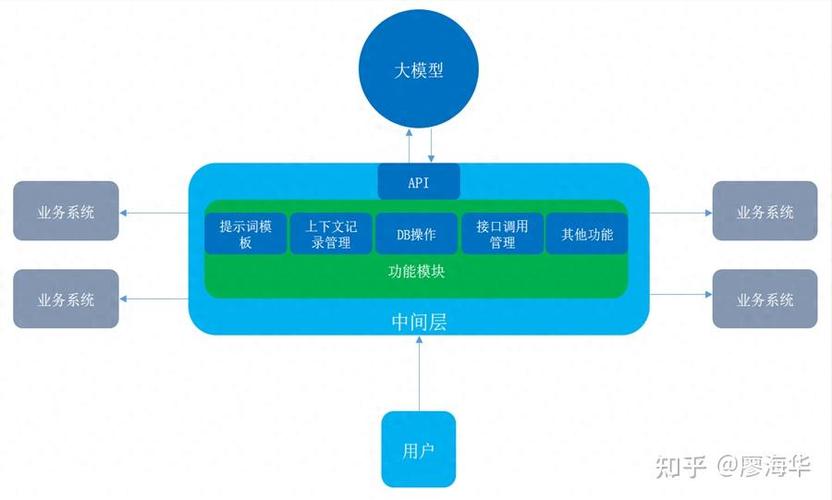
资源整合:技术、数据与人才的协同
技术工具选择
- 开发框架:TensorFlow、PyTorch等主流框架提供预训练模型库(Hugging Face);
- 低代码平台:Azure Machine Learning、Google AI Studio可降低部署难度;
- 算力方案:中小团队可租用云服务器,避免硬件投入。
数据质量优化
大模型对数据敏感,需遵循“少而精”原则:
- 清洗噪声数据(如重复、错误标注内容);
- 补充领域特定数据(如医疗行业需专业术语库);
- 建立数据标注规范,确保一致性。
团队能力建设
- 技术人才:至少需1-2名熟悉Python及深度学习框架的工程师;
- 业务专家:领域知识(如金融、法律)是模型落地的关键;
- 协作模式:采用敏捷开发,分阶段验证模型效果。
实践策略:从试点到规模化
阶段1:最小可行性验证(MVP)
选择单一场景进行测试,例如用开源模型生成产品描述文案,对比人工撰写效率,关键指标包括准确率、响应速度、用户满意度。

阶段2:模型优化与迭代
- 微调(Fine-tuning):使用自有数据调整模型参数,提升特定任务表现;
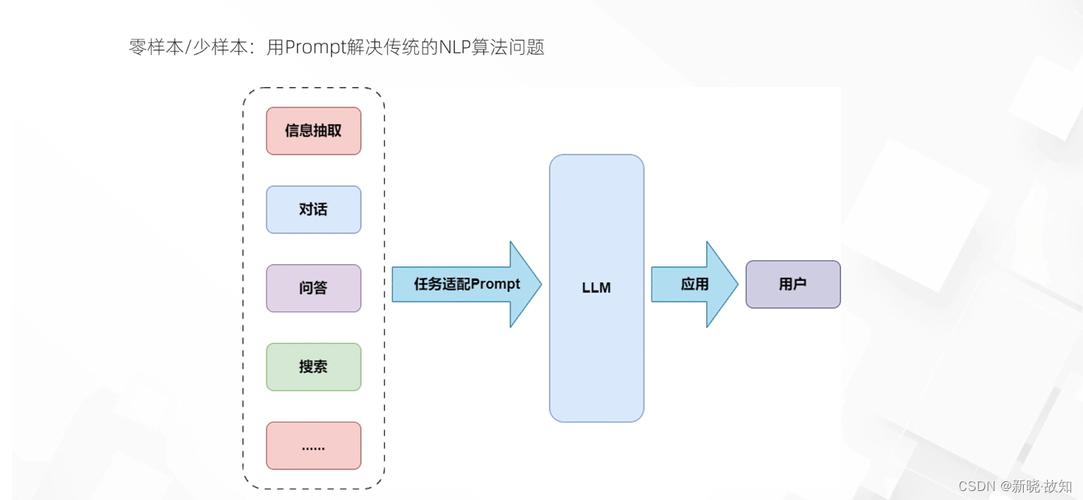
- 提示工程(Prompt Engineering):通过优化输入指令,引导模型输出更符合需求的结果;
- 性能监控:记录模型错误案例,持续优化训练数据。
阶段3:规模化部署
- 自动化流程:将模型嵌入现有系统(如CRM、ERP);
- 安全合规:部署数据脱敏机制,避免隐私泄露风险;
- 用户培训:提供操作指南,降低使用门槛。
风险与伦理:不可忽视的挑战
- 偏见与公平性:训练数据中的偏差可能导致模型输出歧视性内容,需定期审计;
- 版权争议是否涉及知识产权侵权?需建立法律风险评估机制;
- 资源消耗:大模型训练碳排放较高,可优先选择能效优化的云服务商。

 13888888888
13888888888

 点击咨询
点击咨询 