答辩,对每一位投入心血研发AI模型的开发者或团队来说,既是成果展示的舞台,也是能力与专业性的关键检验,面对评审专家犀利的目光,如何清晰、有力、令人信服地阐述模型评估结果,直接决定了项目的认可度,掌握以下核心要点,让你的AI模型评估答辩脱颖而出。
答辩核心:以评估报告为基石
答辩绝非临场发挥的演讲,其根基在于一份扎实、详尽的模型评估报告,这份报告是你答辩内容的蓝图,务必在答辩前精心打磨:
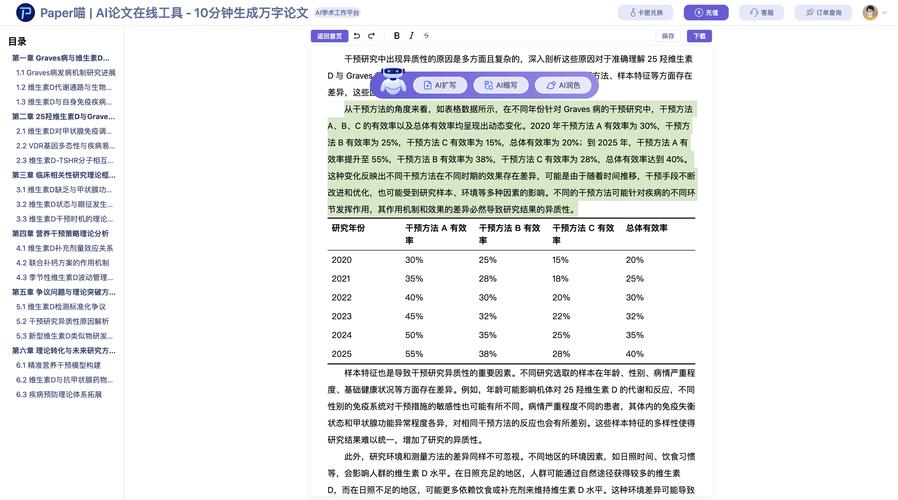
- 目标明确,紧扣需求: 开宗明义,清晰阐述模型要解决的核心业务问题或技术目标,评估指标的选择必须紧密围绕这些目标,一个用于金融欺诈检测的模型,召回率(Recall)可能比准确率(Accuracy)更重要;一个图像分类模型,Top-5准确率可能比Top-1更有实际意义。
- 数据为本,透明可信:
- 数据集清晰: 明确说明训练集、验证集、测试集的来源、规模、构成及划分方法,强调数据预处理步骤(清洗、增强、标准化等)及其必要性。
- 数据代表性: 论证所用数据能充分代表模型将要面对的真实场景,避免因数据偏差导致评估失真,提及对潜在数据偏见的识别和缓解措施(如有)。
- 指标全面,解读深入:
- 选择恰当指标: 根据任务类型(分类、回归、聚类、生成等)选择业界公认的核心指标(如Accuracy, Precision, Recall, F1, AUC-ROC, MSE, MAE, BLEU, ROUGE等),避免堆砌无关指标。
- 超越单一数字: 单一指标往往具有欺骗性,务必进行多维分析:
- 混淆矩阵: 直观展示分类错误的具体分布(哪些类别易混淆?)。
- ROC曲线与AUC: 评估模型在不同阈值下的整体性能,尤其关注排序能力。
- PR曲线: 在数据不平衡时,比ROC曲线更能反映模型在正例上的表现。
- 误差分析: 深入分析模型在哪些样本或场景下表现不佳?是数据问题、特征问题还是模型结构限制?展示具体错误案例(脱敏后)。
- 基准对比: 将模型性能与合理的基线(如简单规则、经典算法、前期版本或公开SOTA模型)进行对比,凸显改进与优势。
- 实验严谨,可复现:
- 超参数与配置: 详细记录关键超参数(学习率、批次大小、正则化强度、网络结构等)的选择依据和调优过程(如网格搜索、贝叶斯优化)。
- 随机性控制: 明确随机种子设置,确保实验结果可复现。
- 消融实验: 如果模型包含多个创新模块或技术,进行消融实验,量化证明每个组件的贡献。
- 局限性坦诚,未来可期: 客观分析模型当前存在的不足(如对某些边缘案例处理不佳、计算资源消耗大、依赖特定数据假设等),这不仅体现专业性,也为未来优化指明方向。
答辩表达:清晰、有力、说服力强
有了坚实的报告基础,答辩就是如何高效传达这些信息:
- 结构为王,逻辑清晰:
- 黄金开场 (1-2分钟): 快速切入主题,用一两句话点明模型要解决的核心问题及其重要性,清晰陈述评估的核心结论(“我们的模型在关键指标X上达到了Y,显著优于基线Z”)。
- 背景与目标 (1-2分钟): 简述项目背景、模型设计目标、预期解决的痛点。
- 数据与方法精要 (2-3分钟): 聚焦关键数据信息和核心评估方法/指标的选择理由,避免陷入技术细节泥潭。
- 核心评估结果 (核心部分,5-8分钟):
- 聚焦亮点: 重点展示最能证明模型价值和优势的评估结果(主要指标、对比结果)。
- 可视化是利器: 大量使用清晰、专业的图表(折线图、柱状图、混淆矩阵热力图、ROC/PR曲线、误差示例图),图表标题、坐标轴标签务必清晰易懂,一图胜千言。
- 解读重于呈现: 不要仅仅展示数字或图表,要解读其含义:“从混淆矩阵可以看出,模型主要将A类误判为B类,这可能源于训练数据中这两类样本特征的相似性...”。
- 深入误差分析: 展示对失败案例的深入剖析,体现你对模型的理解深度和解决问题的思路。
- 讨论与局限 (1-2分钟): 坦诚讨论模型的局限性、当前评估的潜在不足(如测试集分布可能与未来线上数据有差异)、以及这些局限性对实际应用的影响。
- 总结与展望 (1分钟): 再次简洁有力地重申核心成果和价值,并简要提及基于评估结果的下一步优化计划或应用展望。
- 表达精准,从容自信:
- 术语适度: 使用必要的专业术语,但确保评委(即使非完全同领域)能理解核心概念,对关键术语可稍作解释。
- 语速平稳: 保持适中语速,重点处可稍作停顿强调,避免因紧张而语速过快。
- 眼神交流: 与评委进行自然的目光接触,展现自信和真诚。
- 应对提问: 预留充足时间给问答环节,认真倾听问题,确认理解无误后再回答,对于不确定的问题,坦诚说明,承诺后续查证补充,切忌胡编乱造,对于质疑,保持冷静,用评估数据和逻辑进行回应。
- 突出E-A-T:贯穿始终的专业性
- 专业性 (Expertise): 展示对模型原理、评估方法、领域知识的深刻理解,引用权威文献或标准(如指出所选指标是某领域常用标准),体现严谨的实验设计和科学态度。
- 权威性 (Authoritativeness): 数据来源可靠(如公开基准数据集、经过严格处理的业务数据),方法遵循最佳实践,结果可复现,引用公认的工具(如TensorFlow, PyTorch, scikit-learn)和评估库。
- 可信度 (Trustworthiness): 数据透明、实验过程可追溯、结果解读客观(不夸大优势,不回避缺点)、对局限性和风险坦诚,展现对模型实际落地应用的负责任态度。
答辩准备:细节决定成败

- 演练!演练!演练! 多次计时演练,确保内容在规定时间内完成,邀请同事模拟评委提问。
- PPT精炼: PPT是辅助工具,文字要极其精炼,多用图表,确保字体够大、配色清晰、排版专业,每页传递一个核心信息。
- 时间管理: 严格把控每个环节的时间,宁可少讲一点细节,也要保证核心逻辑完整,准备“精简版”内容以应对时间压缩。
- 了解你的评委: 尽可能了解评委的背景(技术专家?业务方?),调整讲述的侧重点和术语深度。
- 心态调整: 答辩是交流和学习的机会,保持积极心态,展现你对工作的热情和投入。
最终致胜关键: AI模型评估答辩的成功,本质在于用扎实的证据(数据、指标、分析)、清晰的逻辑(结构、表达)和专业的素养(E-A-T),向评委证明你的模型不仅有效,而且其效果是可衡量、可解释、可信赖的,你对模型优缺点的深刻洞察和坦诚态度,往往比完美的指标更能赢得尊重和信任,站在台上时,记住你比任何人都更了解这个模型和它的评估历程,这份自信来源于充分的准备和对细节的极致追求。

 13888888888
13888888888

 点击咨询
点击咨询 