人工智能训练模型的生成过程
人工智能训练模型的生成,是一个复杂而精细的过程,涉及多个关键阶段,作为网站站长,我经常与AI开发者交流,深知这一过程如何塑造现代技术应用,生成AI模型就像培养一位专家:需要高质量的数据作为基础,精密的算法作为工具,以及强大的计算资源作为支撑,整个过程始于数据准备,逐步推进到模型训练和最终部署,每一步都至关重要,本文将详细拆解这些步骤,帮助读者理解AI模型从无到有的诞生之旅。
数据准备是模型生成的基石,没有可靠的数据,AI模型就无法学习,这一阶段包括数据收集、清洗和预处理,训练一个图像识别模型时,开发者会搜集数百万张标注图片,如猫和狗的图片,并确保每张图都准确标记类别,数据清洗环节至关重要,它去除无效或错误信息,比如模糊图像或重复条目,预处理则涉及标准化数据格式,例如将图片调整为统一尺寸或归一化像素值,这能提升模型训练的效率和准确性,数据质量直接影响最终效果,因此开发者必须投入大量时间验证来源的真实性和多样性,避免偏见问题,如确保数据集涵盖不同品种的动物,在我观察中,许多失败案例源于数据不足或不均衡,导致模型在实际应用中表现不佳。
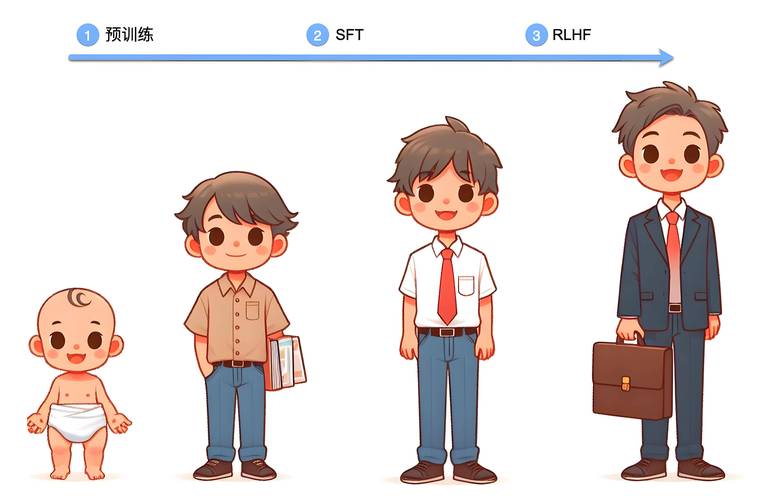
模型设计阶段决定了AI的学习框架,开发者选择适合任务的算法架构,如卷积神经网络用于图像处理,或Transformer模型用于语言任务,这一步骤需要专业知识,因为模型结构直接影响训练效率和结果,设计一个聊天机器人模型时,开发者会选取预训练语言模型作为基础,然后根据具体需求调整层数和参数,模型设计不是一成不变的;它涉及反复迭代和实验,以优化性能,计算资源在这里扮演关键角色,训练大型模型通常需要GPU集群或云计算平台,处理海量计算任务,资源不足可能导致训练过程漫长或失败,根据我的经验,小团队往往从开源框架如TensorFlow或PyTorch起步,逐步扩展规模。
进入训练过程,这是模型生成的核心环节,训练本质上是让模型通过数据学习模式和规律,开发者将准备好的数据输入模型,利用算法如梯度下降来调整内部参数,这一过程分批次进行:每次输入一小批数据,模型计算预测结果,对比真实标签,计算误差(损失函数),然后反向传播更新参数,迭代次数称为epochs,过多可能导致过拟合(模型记忆数据而非学习泛化),过少则欠拟合(模型无法捕捉复杂模式),监控和调整超参数如学习率至关重要,训练环境需稳定,使用分布式系统加速计算,训练一个推荐系统模型时,开发者会实时监控损失曲线,添加正则化技术防止过拟合,训练可能耗时数天甚至数周,消耗大量电力资源,这阶段挑战包括硬件故障或数据漂移,开发者需设置检查点保存进度。
训练完成后,评估和验证确保模型可靠,开发者使用独立测试数据集检验模型性能,避免在训练数据上自欺欺人,评估指标如准确率、召回率或F1分数量化模型表现,一个医疗诊断模型需达到高精度以避免误诊,验证还包括公平性测试,检查模型是否对不同群体无偏见,失败模型需返回训练阶段调整,验证通过后,模型进入部署阶段,集成到应用如APP或网站中,部署后,持续监控和更新必不可少,因为现实数据会变化,模型需定期再训练保持效果。
生成AI模型面临诸多挑战,数据隐私和伦理问题日益突出,开发者必须遵守法规如GDPR,确保数据匿名处理,资源消耗也是瓶颈,训练大模型可能排放大量碳足迹,推动行业探索绿色AI方案,模型解释性不足让用户难以信任黑箱决策,解决这些需要跨学科合作,结合领域专家知识优化过程。

从个人视角,我认为AI训练模型的生成正推动人类创新边界,它不只属于技术精英;开源工具让更多人参与, democratizing AI潜力巨大,模型将更高效、更透明,助力医疗、教育等领域,但我们必须平衡进步与责任,确保AI服务于社会福祉,而非加剧不平等,作为实践者,我鼓励读者探索这一领域,亲身参与变革。

 13888888888
13888888888

 点击咨询
点击咨询 