AI语言模型:从简单规则到智能对话的进化之路
你是否好奇过,手机输入法如何预测你即将输入的文字?智能客服为何能理解你的问题?这一切的核心,就是人工智能领域的明星技术——AI语言模型,它们的诞生并非一蹴而就,而是一场融合了人类智慧与计算能力的漫长探索。
萌芽:规则与统计的早期尝试 最初的探索始于“规则驱动”的思路,科学家们尝试手动编写庞大复杂的语法规则词典,教机器理解语言结构,设定“名词后接动词”等规则,语言灵活多变,充满例外与歧义,这种方法很快遇到瓶颈。
随后,“统计学习”方法登上舞台,研究者让计算机分析海量文本数据,学习词语之间的共现规律,通过统计发现“猫”常与“捉”、“鱼”、“可爱”等词一起出现,而“编程”则高频伴随“代码”、“算法”、“学习”,这种方法催生了早期机器翻译和简单的文本预测工具,效果远胜于规则系统,但理解深度依然有限,难以把握上下文和语义。
突破:神经网络的智慧觉醒 真正的革命始于“神经网络”的深度应用,科学家借鉴人脑神经元的工作方式,构建了多层网络结构来处理语言数据,关键一步是“词嵌入”技术——将单词转化为蕴含语义信息的稠密向量(一串有意义的数字),神奇之处在于,在这个数字空间中,语义相近的词(如“国王”与“王后”)距离很近,甚至能进行类比运算(“国王”-“男人”+“女人”≈“王后”)。

循环神经网络(RNN)及其改进版本长短时记忆网络(LSTM)的出现,让模型首次具备了一定程度的“记忆”能力,可以处理前后关联的序列信息(如一个句子),理解更复杂的上下文关系,2018年左右,ELMo等模型创新性地提出根据上下文动态调整词义表示,解决了“苹果”在指水果还是公司时含义不同的问题,理解精度大幅提升。
爆发:Transformer与大模型时代 2017年,谷歌团队提出的“Transformer”架构彻底改变了游戏规则,其核心“自注意力机制”允许模型在处理某个词时,同时关注并衡量句子中所有其他词的重要性权重,这就像阅读时,大脑能瞬间聚焦于关键信息,忽略次要部分,实现了对长距离上下文的精准把握和高效并行计算。
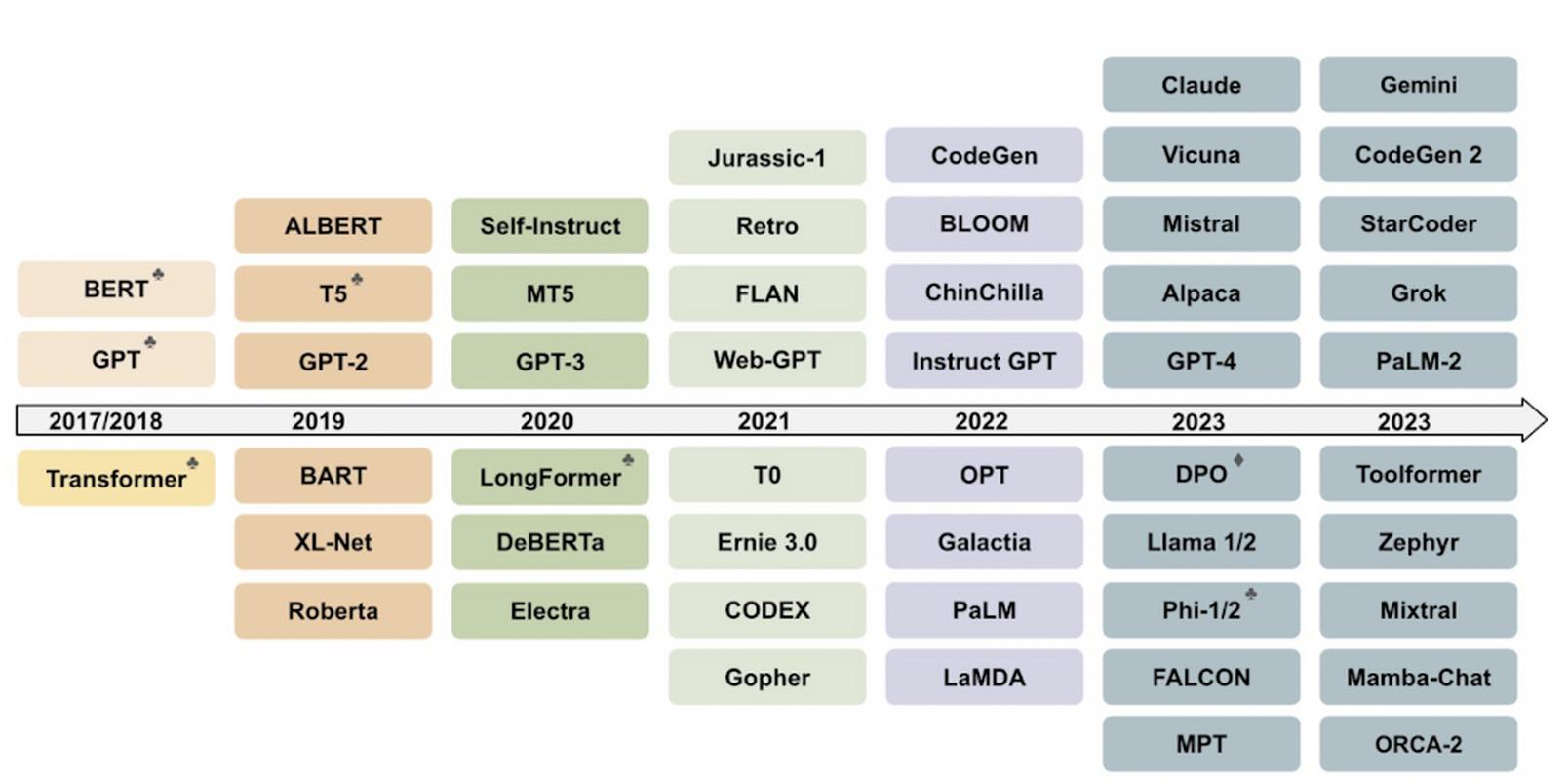
Transformer催生了划时代的模型家族:
- GPT系列(OpenAI):专注于“生成式”预训练,通过海量文本学习预测下一个词,掌握了强大的文本续写和创作能力,擅长对话、写作等任务。
- BERT(谷歌):采用“双向”预训练,同时考虑上下文左右两侧的信息,在问答、语义理解等任务上表现卓越。
这些模型首先在包含书籍、网页、百科等组成的超大规模语料库上进行“预训练”,学习语言的通用模式和知识,随后,通过特定领域或任务的少量数据进行“微调”,快速适应具体应用场景(如法律文书分析、医疗问答),模型的参数量也从百万、十亿级一路飙升至千亿(如GPT-3)甚至万亿级别,更大的模型、更丰富的数据,带来了更惊人的语言理解、生成和推理能力。
挑战与未来 语言模型的进化远未停止,当前研究聚焦于提升“推理能力”、“事实准确性”和降低“幻觉”(生成不实信息)风险,多模态模型(如GPT-4V、Gemini)正整合文本、图像、声音等信息,向更全面的人工智能迈进,模型效率优化和普惠化部署也是重要方向。
观点: AI语言模型的发展是人类智慧与工程伟力的结晶,它为我们打开了便捷信息交互的大门,它终究是工具而非替代者,其价值在于辅助我们更高效地创造、理解和连接,在拥抱其强大能力的同时,保持对技术边界的清醒认知和对人类独特智慧价值的珍视,才是驾驭未来的关键。

 13888888888
13888888888

 点击咨询
点击咨询 