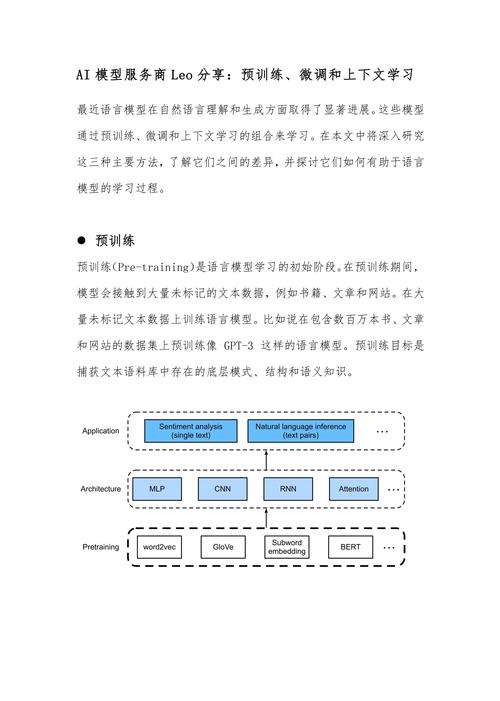
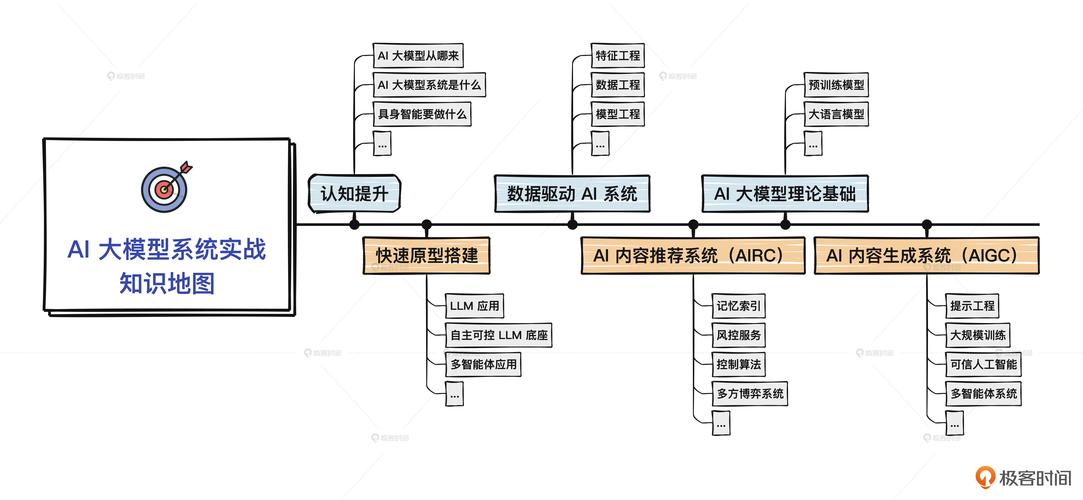
超脑AI模型部署实战指南:从准备到上线的关键步骤
将强大的超脑AI模型成功部署到您的应用环境中,是释放其智能潜力的关键一步,这个过程需要严谨的技术规划和细致的操作,无论您是经验丰富的工程师还是技术决策者,掌握正确的部署方法都至关重要,以下是如何高效、安全地实现超脑AI模型部署的详细指引:
周密准备:奠定部署基石
-
深度解析模型需求:
- 框架锁定: 精确识别模型训练所使用的深度学习框架(如TensorFlow、PyTorch、PaddlePaddle),这直接决定了后续转换工具或运行环境的选择。
- 资源评估: 详细计算模型推理所需的计算资源:
- GPU/算力卡: 型号(如NVIDIA A100/V100、国产算力卡)、显存容量(务必大于模型权重文件大小+批处理数据所需空间)、数量需求。
- CPU与内存: 复杂预处理/后处理逻辑或大模型可能需要强劲CPU与充足RAM。
- 存储: 高速存储(如NVMe SSD)对于快速加载大型模型权重至关重要。
- 网络: API服务需评估带宽与并发吞吐量。
-
构建目标运行环境:
- 软件栈精确配置:
- 操作系统: 选择稳定版本(如Ubuntu LTS, CentOS Stream)。
- 驱动与库: 安装GPU厂商官方驱动(如NVIDIA Driver)、对应的CUDA/cuDNN Toolkit(版本需严格匹配框架要求)、框架特定加速库(如TensorRT for TensorFlow/PyTorch, ONNX Runtime)。
- Python环境: 使用
virtualenv或conda创建隔离环境,依据模型要求安装指定版本的Python解释器及所有依赖包 (pip install -r requirements.txt),版本一致性是避免兼容性问题的核心。
- 硬件验证: 运行
nvidia-smi(GPU)、lscpu(CPU)、free -h(内存)、df -h(存储)等命令,确认资源可用性与容量符合预期。
- 软件栈精确配置:
模型加载与转换:核心环节
-
获取模型资产: 确保拥有完整的模型文件包,通常包含:
- 训练好的模型权重文件(如
.ckpt,.pth,.h5,.pb)。 - 模型结构定义文件(代码或序列化文件如
.pb,.onnx)。 - 预处理/后处理逻辑代码或配置文件。
- 可选的词汇表、标签映射文件等。
- 训练好的模型权重文件(如
-
模型格式转换(如需):
- 为何转换? 提升推理效率(TensorRT)、实现跨框架部署(ONNX)、适配特定推理引擎。
- 主流转换路径:
- PyTorch -> ONNX:
torch.onnx.export(model, dummy_input, "model.onnx"),务必验证导出后模型精度。 - TensorFlow -> TensorRT: 使用
tf2onnx转ONNX,再用trtexec转TensorRT Engine;或直接使用TF-TRT API。 - PyTorch -> TensorRT: 通过ONNX中转或使用
torch2trt工具。 - 框架原生格式: 若环境支持原生框架(如PyTorch直接加载
.pt),可跳过转换,但可能牺牲部分优化性能。
- PyTorch -> ONNX:
- 转换验证: 此步骤不可或缺! 在目标环境中,使用转换后的模型对一组样本进行推理,与原始框架结果严格比对,确保精度损失在可接受范围内,关注动态尺寸(如可变输入序列长度)是否被正确处理。
集成与推理:让模型运转起来
-
加载模型到内存:
- 使用对应框架或推理引擎的API加载转换后或原生的模型文件。
- 示例 (PyTorch):
import torch model = torch.jit.load('traced_model.pt') # 加载TorchScript模型 model.eval() # 设置为评估模式 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) - 示例 (ONNX Runtime):
import onnxruntime as ort sess_options = ort.SessionOptions() # 可配置线程数、优化选项等 session = ort.InferenceSession("model.onnx", sess_options, providers=['CUDAExecutionProvider']) # 指定GPU执行
-
实现推理流程:
- 数据预处理: 严格复现训练时的处理流程(归一化、缩放、编码等),确保输入数据格式、维度与模型要求一致,常用库:OpenCV, Pillow, NumPy, Scikit-learn。
- 执行推理: 调用模型API进行预测。
# PyTorch 示例 with torch.no_grad(): inputs = torch.tensor(preprocessed_data).to(device) outputs = model(inputs)# ONNX Runtime 示例 input_name = session.get_inputs()[0].name output_name = session.get_outputs()[0].name outputs = session.run([output_name], {input_name: preprocessed_data}) - 结果后处理: 将模型原始输出(如logits、概率分布)转换为业务可用的结果(类别标签、检测框、文本等)。
部署上线与严格验证
-
封装服务接口:
- 将推理流程封装成可调用服务:
- API服务: 使用Flask, FastAPI, Django REST Framework等构建RESTful/gRPC API。
- 微服务: 容器化(Docker)部署,方便扩展和管理。
- 集成SDK: 提供语言特定SDK供内部应用调用。
- 关键考量: 输入验证、错误处理、日志记录、性能监控(响应时间、吞吐量)。
- 将推理流程封装成可调用服务:
-
全面测试:
- 功能正确性: 使用涵盖各类场景(特别是边界案例)的测试数据集验证输出结果是否符合预期。
- 性能压测: 模拟高并发请求(工具如Locust, JMeter),评估:
- 吞吐量(QPS/TPS)
- 平均响应时间、P99延迟
- 资源利用率(GPU/CPU/内存)
- 稳定性测试: 长时间运行,检查内存泄漏、资源耗尽等问题。
- 安全测试: 防范对抗攻击、输入注入等风险。
持续维护:保障长期稳定
- 性能监控: 实时跟踪API延迟、错误率、资源使用率(GPU显存、利用率、温度)。
- 日志与追踪: 记录详细推理日志(输入、输出、耗时),集成分布式追踪(如Jaeger)排查问题。
- 模型更新: 建立安全可靠的模型热更新或滚动更新流程,避免服务中断。
- 版本控制: 严格管理模型文件、预处理代码、服务代码的版本,确保可追溯和回滚。
- 文档更新: 维护最新的部署文档、接口文档、问题排查指南。
关键风险与规避策略
- 环境差异陷阱: 训练环境与部署环境软件库、驱动版本不一致是常见错误源头。解决之道: 使用容器化技术(Docker)封装整个运行环境;或利用精确的依赖管理工具锁定版本。
- 硬件兼容性问题: 特定优化(如TensorRT)可能高度依赖GPU架构。解决之道: 在目标硬件上完成最终转换和测试;如支持多种硬件,需准备多份优化模型或使用兼容性更好的中间格式(如ONNX搭配ONNX Runtime)。
- 预处理/后处理不一致: 此环节错误导致模型表现异常。解决之道: 将预处理/后处理代码模块化、版本化,并与模型一同部署;编写单元测试确保一致性。
- 资源估算不足: 低估并发量或模型资源需求导致服务崩溃。解决之道: 基于压测结果进行容量规划,实施弹性伸缩策略(Kubernetes HPA)。
- 忽略动态维度: 模型需处理可变尺寸输入(如图像、文本)。解决之道: 在转换/加载时明确支持动态轴(ONNX/TensorRT);或服务层进行填充/截断标准化。
部署超脑AI模型并非简单的文件传输,而是融合环境工程、性能优化与持续运维的系统工程,理解模型特性、精确配置环境、严格验证流程、建立监控机制,才能确保模型在生产环境中高效、稳定、可靠地运行,真正将前沿的AI能力转化为实际业务价值,每一次严谨的部署都是对智能潜力的一次成功释放。

 13888888888
13888888888

 点击咨询
点击咨询 