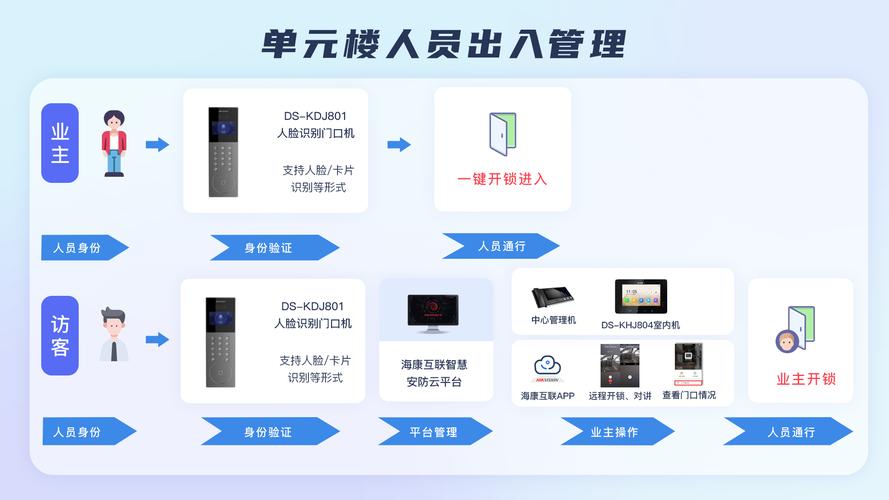
海康AI模型导入电脑全流程详解
掌握将海康威视训练好的AI模型成功部署到本地电脑,是解锁其强大智能分析能力的关键步骤,本指南提供清晰、专业的操作流程。
核心准备:模型与环境的基石
-
获取海康AI模型文件:
- 来源: 模型通常来源于海康AI开放平台(iVMS-8810 AI)训练完成并导出的结果,或由海康相关工具(如行业专用训练平台)生成。
- 格式识别: 海康模型常见格式包括:
- HIK (.onnx/.hknn/.hkmodel): 海康自研或优化后的模型格式,
.onnx是其常用的开放格式变体,.hknn或.hkmodel可能是其私有优化格式(需使用海康特定推理引擎)。 - ONNX (Open Neural Network Exchange): 通用开放格式,兼容性强,是海康平台导出的重要选项。
- TensorRT Engine (.engine): 如模型针对NVIDIA GPU进行了TensorRT加速优化,可能会提供此格式。
- HIK (.onnx/.hknn/.hkmodel): 海康自研或优化后的模型格式,
- 关键文件: 除模型文件本身,通常还需配套的模型配置文件(描述输入输出、预处理参数等)和标签文件(定义识别类别)。
-
配置本地计算环境:
- 硬件考量:
- CPU: 通用性强,适合轻量级模型或没有GPU的环境,确保性能足够(如Intel i5/i7或AMD Ryzen 5/7及以上)。
- GPU (推荐): 大幅加速模型推理,主流选择是NVIDIA GPU(如GTX/RTX系列或专业级Tesla/Quadro),务必安装匹配的NVIDIA显卡驱动。
- 软件栈搭建:
- 推理框架: 选择与模型格式匹配的框架:
- OpenVINO™ Toolkit (Intel): 对Intel CPU/集成显卡优化极佳,支持ONNX等格式。
- TensorRT (NVIDIA): 专为NVIDIA GPU优化,支持ONNX转换为
.engine或在支持框架中直接加载ONNX(使用TensorRT后端)。 - ONNX Runtime: 跨平台、跨硬件的高性能推理引擎,支持CPU/GPU(CUDA/DirectML),兼容ONNX模型。
- 海康专用推理SDK: 若模型为
.hknn等私有格式,必须使用海康提供的对应SDK或库进行加载和推理。
- 深度学习框架 (可选但常见): 如PyTorch, TensorFlow,某些场景下可直接加载其原生格式模型(需确认海康是否支持导出),或作为ONNX Runtime的后端。
- Python环境: 绝大多数推理示例和工具链基于Python,推荐使用
conda或venv创建独立虚拟环境,安装必要的库:- 基础:
numpy,opencv-python(图像处理) - 对应框架:
onnxruntime/onnxruntime-gpu,openvino,tensorrt,torch,tensorflow等。 - 海康SDK:按官方文档要求安装。
- 基础:
- CUDA/cuDNN (GPU必需): 若使用NVIDIA GPU加速,需安装与显卡驱动和框架要求匹配的CUDA Toolkit和cuDNN库。
- 推理框架: 选择与模型格式匹配的框架:
- 硬件考量:
模型导入与加载实战
-
模型放置与路径管理
- 将获取到的模型文件(
.onnx,.engine,.hknn等)、配置文件(如.json,.prototxt)、标签文件(如.txt,.names)整理存放在电脑的特定目录下(如project/models/your_model/)。 - 在代码中,使用绝对路径或相对于脚本位置的相对路径明确指定这些文件的位置,避免路径错误。
- 将获取到的模型文件(
-
使用推理框架加载模型
-
ONNX Runtime (示例):
import onnxruntime as ort # 选择执行提供者:CPU 或 CUDA (GPU) providers = ['CUDAExecutionProvider', 'CPUExecutionProvider'] # 优先尝试GPU # providers = ['CPUExecutionProvider'] # 仅使用CPU # 创建推理会话 model_path = 'path/to/your_model.onnx' session = ort.InferenceSession(model_path, providers=providers) # 获取模型输入输出信息 input_name = session.get_inputs()[0].name output_name = session.get_outputs()[0].name
-
OpenVINO (示例):
from openvino.runtime import Core ie = Core() model = ie.read_model(model='path/to/your_model.xml') # .xml 是OpenVINO IR模型文件 # 如果只有ONNX,通常需要先使用OpenVINO的Model Optimizer工具转换 # $ mo --input_model your_model.onnx compiled_model = ie.compile_model(model=model, device_name='GPU') # 或 'CPU' # 获取输入输出信息 input_layer = compiled_model.input(0) output_layer = compiled_model.output(0)
-
TensorRT (加载ONNX示例,需先转换或直接加载engine):
# 使用ONNX Runtime + TensorRT EP (较简单) import onnxruntime as ort providers = ['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'] sess_options = ort.SessionOptions() # 可能需要设置TRT引擎缓存路径等选项 session = ort.InferenceSession('path/to/your_model.onnx', sess_options, providers=providers) # 直接加载.engine文件通常使用TensorRT原生Python API (更底层) -
海康专用SDK (参考官方文档):
- 流程通常涉及:初始化SDK -> 创建模型句柄 -> 加载模型文件(
.hknn等)-> 配置参数(如阈值)。 - 具体API调用需严格遵循海康提供的开发手册和示例代码。
- 流程通常涉及:初始化SDK -> 创建模型句柄 -> 加载模型文件(
-
-
预处理配置对接
- 模型配置文件至关重要,它明确规定了输入数据的:
- 尺寸 (Height, Width): 如
640x640。 - 通道顺序: 通常是
BGR或RGB。 - 归一化方式: 如
mean=[0, 0, 0],std=[255, 255, 255](即除以255) 或特定值mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375]。 - 数据布局:
NCHW(批次, 通道, 高, 宽) 或NHWC。
- 尺寸 (Height, Width): 如
- 在代码中,使用OpenCV等库读取输入数据(图片/视频帧),严格按照配置要求进行缩放、颜色空间转换(如
cv2.cvtColor(img, cv2.COLOR_BGR2RGB))、归一化(如img = (img - mean) / std)、维度变换(如np.transpose(img, (2, 0, 1))得到CHW,再np.expand_dims得到NCHW)。
- 模型配置文件至关重要,它明确规定了输入数据的:
-
执行推理与解析结果
- 将预处理后的数据(numpy数组)传递给加载好的模型会话。
# 以ONNX Runtime为例 input_data = preprocessed_image.astype(np.float32) # 确保数据类型正确 outputs = session.run([output_name], {input_name: input_data})[0] - 输出的
outputs结构由模型决定(查看模型信息或配置文件),常见形式:- 目标检测:
[batch, num_boxes, 5+num_classes](中心x, 中心y, 宽, 高, 置信度 + 各类别分数)。 - 图像分类:
[batch, num_classes](各类别概率)。
- 目标检测:
- 编写后处理代码解析原始输出:
- 目标检测:应用置信度阈值过滤 -> 非极大值抑制 (NMS) 去除重叠框 -> 将归一化坐标转换回原图坐标 -> 根据标签文件映射类别ID到名称。
- 图像分类:取
argmax或top-k获取最高概率类别ID -> 映射到标签名称。
- 将预处理后的数据(numpy数组)传递给加载好的模型会话。
关键要点与常见问题
- 格式匹配是前提: 确认电脑端推理框架能支持海康导出的模型格式,ONNX是目前兼容性最好的桥梁格式,遇到私有格式,必须使用官方SDK。
- 环境依赖不容忽视: GPU加速需严格匹配驱动、CUDA、cuDNN、框架版本的兼容性,使用
conda管理环境可减少冲突,务必参考框架和硬件的官方安装指南。 - 预处理一致性: 模型在训练和部署时的预处理(尺寸、归一化参数)必须完全一致,否则精度会显著下降甚至失效,仔细核对配置文件。
- 性能调优: 模型加载后,首次推理可能较慢(涉及初始化、优化图),对于实时应用,关注平均推理延迟和吞吐量,可尝试框架提供的优化选项(如OpenVINO的
perf_count模式、TensorRT的FP16/INT8量化)。 - 资源占用监控: 使用任务管理器、
nvidia-smi(GPU) 或htop(Linux CPU) 监控模型运行时的CPU、GPU和内存占用,确保资源充足。 - 错误排查:
- 模型加载失败: 检查文件路径是否正确、文件是否损坏;确认框架版本是否支持该模型算子集(ONNX模型常见问题);检查CUDA/cuDNN安装和版本兼容性(GPU加载失败)。
- 输入维度/类型错误: 仔细核对代码中的输入数据形状(
shape)、数据类型(dtype)是否与模型输入要求完全一致。 - 输出解析错误: 理解模型输出结构,对照文档或模型信息检查后处理代码逻辑是否正确。
- 精度下降: 首要怀疑预处理配置是否与训练时一致(尺寸、均值、方差、颜色通道);其次检查模型转换过程(如ONNX转OpenVINO IR/TensorRT Engine)是否有警告或精度损失。
模型应用场景
成功导入模型至电脑后,即可在本地运行,应用于广泛场景:
- 离线视频/图片分析: 对本地存储的视频文件或图片文件夹进行批量智能分析(目标检测、行为识别、属性分析)。
- 开发与测试: 在本地PC上快速迭代和调试基于海康模型的应用程序,无需依赖云端或设备端环境。
- 原型验证: 在部署到边缘设备或服务器集群前,在本地验证模型性能和效果。
- 集成到本地系统: 将模型推理能力嵌入到自主开发的PC端软件系统中。
导入海康AI模型到电脑是一个涉及环境配置、格式转换、接口对接的系统过程,清晰的流程规划和仔细的操作,能确保模型的智能潜力在本地环境得到稳定高效释放,为后续开发与应用奠定坚实基础,实际操作中遇到细节障碍,查阅海康官方文档和对应推理框架的社区资源通常是最高效的解决途径。

 13888888888
13888888888

 点击咨询
点击咨询 