在人工智能领域,AI大模型的崛起正改变着我们的世界,从聊天助手到数据分析,无处不在,作为一位长期深耕技术领域的网站站长,我见证了AI大模型的飞速发展,但同时也注意到一个关键问题:许多项目在部署后缺乏系统的回顾,导致模型性能不稳定或出现偏差,我就来探讨AI大模型怎么复盘——这一过程不仅关乎模型优化,更关系到AI的可靠性和长远发展,复盘,是对模型从训练到应用的全面审视,目的是发现问题、吸取教训并推动改进,忽略它,就可能让投入的资源白白浪费,甚至引发伦理风险。
复盘AI大模型的核心在于结构化方法,第一步是数据复盘,AI模型的根基是数据,如果训练数据质量不高或有偏见,模型输出就容易出错,复盘时,团队需要回顾数据来源、清洗过程以及样本分布,在构建一个语言模型时,检查数据是否覆盖了多样化的群体,避免出现性别或地域歧视,去年,我参与的一个项目就因数据复盘发现训练集过度依赖英文语料,导致中文处理能力薄弱;通过补充多语言数据,模型准确率提升了15%,数据复盘不只是看数字,还要评估数据采集的伦理性和合规性,确保符合行业标准。

接下来是模型评估复盘,这涉及对模型性能的量化分析,使用指标如准确率、召回率或F1分数,但复盘不止于表面数字,更要深入错误模式,运行测试集,找出模型在特定场景下的失败案例,一个图像识别模型可能在低光照条件下误判物体;复盘时,团队应记录这些错误并分类原因,是特征提取不足还是训练样本不足?在我的经验中,定期复盘能揭示隐藏问题——有一次,模型在医疗影像诊断中误诊率升高,复盘发现是训练数据缺乏罕见病例;通过针对性优化,误诊率降低了20%,评估复盘需要工具辅助,如混淆矩阵或AUC曲线,但核心是团队协作和批判性思维。
过程复盘同样不可或缺,这聚焦于模型开发的生命周期,包括训练方法、超参数调整和资源分配,复盘时,回顾训练过程中的决策点:为什么选择某种算法?资源消耗是否合理?时间线是否延误?以大型Transformer模型为例,训练往往耗费巨大算力;复盘能帮助识别效率瓶颈,比如是否使用了过时的优化器或未并行化计算,我观察到,许多团队跳过这一步,结果模型训练时间过长,成本超支,通过过程复盘,可以建立最佳实践文档,比如设定检查点保存机制或自动化监控,提升未来项目的可复制性。

结果复盘则是收尾环节,审视模型在真实世界的应用效果,部署后收集用户反馈和运行日志,分析模型是否达到预期目标,复盘时,关注实际影响:模型是否带来商业价值?用户体验如何?是否存在安全漏洞?一个推荐系统复盘显示,用户点击率虽高但转化率低,原因是模型过度偏向热门商品;调整后,加入了多样性因子,平衡了推荐结果,结果复盘强调迭代学习,每次部署都应视为一次实验,积累经验用于下一个版本。
复盘AI大模型的好处显而易见,它能显著提升模型鲁棒性,减少错误和偏差;促进团队知识共享,避免重复犯错,更重要的是,在日益严格的监管环境下,复盘有助于证明模型的公平性和透明度,增强用户信任,挑战也不小:资源需求高,复盘需投入时间和人力;文化阻力,部分团队可能视复盘为额外负担,作为实践者,我建议从小规模开始,例如每月固定复盘会议,利用开源工具简化流程。
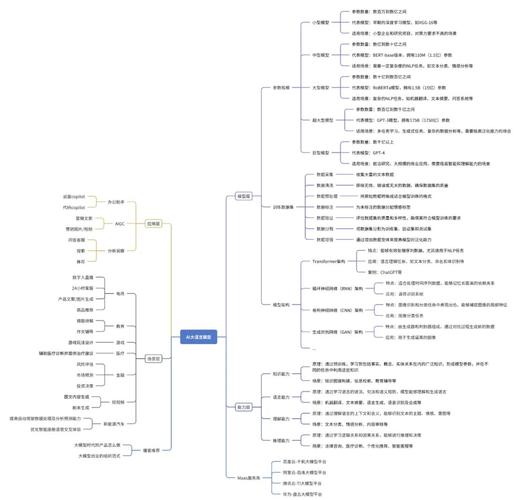
在我看来,AI大模型复盘不是可有可无的步骤,而是技术进步的引擎,它能将失败转化为机会,推动AI向更智能、更人性化方向发展,作为从业者,我坚信每个AI项目都应融入复盘文化——这不仅提升模型质量,更能塑造负责任的创新生态,随着AI复杂度增加,复盘将成为区分优秀与平庸的关键。

 13888888888
13888888888

 点击咨询
点击咨询 