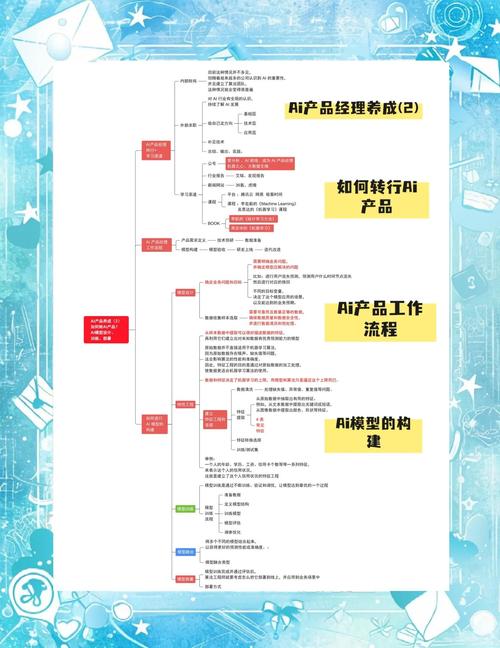
AI模型构建过程:如何清晰记录你的创造之旅
想象一下:你精心设计的AI模型在测试中表现优异,可当团队询问构建细节时,你却难以系统复述关键步骤——这正是规范记录模型构建过程的价值所在,清晰的文档不仅是团队协作的基石,更是模型可复现性、可维护性的核心保障,如何有效书写这一过程?
第一步:明确目标与问题定义(锚定方向) 一切始于精准的问题定义,你需要清晰阐述:
- 核心任务: 模型究竟要做什么?(分类图片?预测销量?生成文本?)
- 成功标准: 如何衡量模型成功?选用准确率、召回率、F1分数、RMSE等具体指标,并说明设定理由。
- 关键约束: 面临哪些现实限制?(数据量不足、计算资源有限、严格的推理延迟要求?)
记录重点:详细描述业务背景、待解决的核心痛点及期望达成的具体目标。“构建一个基于用户评论情感倾向(积极/中性/消极)的分类模型,用于实时监测产品反馈,目标测试集F1分数不低于0.85,单条评论预测延迟小于100毫秒。”
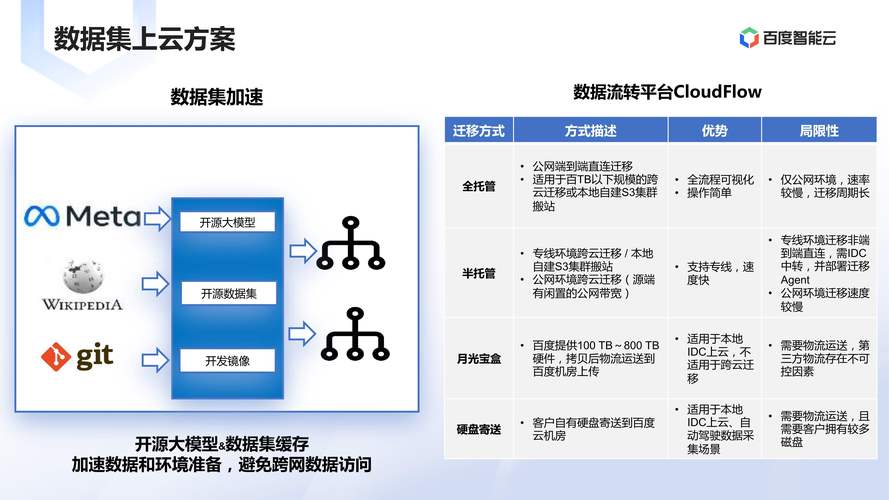
第二步:数据收集与处理(奠定基石) 高质量数据是模型的生命线,此阶段需详尽记录:

- 数据来源: 数据具体从何而来?(内部数据库、公开数据集、爬虫获取?)列出具体数据集名称、版本及获取途径(注意合规性)。
- 数据概况: 进行初始探索性数据分析 (EDA),记录数据量大小、特征数量及类型(数值型、类别型、文本等)、关键特征的统计分布(均值、标准差、缺失率)。
- 预处理流水线: 这是核心记录内容:
- 清洗: 如何处理缺失值?(删除、填充均值/中位数/众数、使用模型预测)?怎样识别并处理异常值?
- 转换: 如何编码类别特征?(独热编码、标签编码、目标编码)?是否对数值特征进行了标准化(如Z-score)或归一化(如Min-Max)?
- 构造: 是否创建了新的特征?(从日期中提取星期几、从文本中提取关键词频率)。
- 划分: 如何划分训练集、验证集和测试集?(比例?是否分层采样以保证分布一致?是否考虑了时间因素?)
记录重点:清晰描述每一步处理操作、使用的具体方法或库(如用Scikit-learn的SimpleImputer处理缺失值)、处理前后的数据变化及决策依据,可视化关键步骤(如缺失值热力图、特征分布对比图)能让记录更直观。
第三步:模型选择与实验(核心探索) 这是算法和工程智慧碰撞的阶段,需严谨记录:
候选模型: 尝试了哪些模型或架构?(如逻辑回归、随机森林、XGBoost、特定的神经网络结构如CNN、Transformer),说明初选理由(基于问题特性或文献经验)。
实验设置: 详细说明:
- 超参数调优: 采用何种策略?(网格搜索、随机搜索、贝叶斯优化)?搜索的具体参数空间范围是什么?
- 交叉验证: 使用几折交叉验证?如何保证有效性?
- 评价指标: 使用哪些指标评估验证集性能?为何选择这些指标?
实验结果: 这是关键证据,用表格清晰列出不同模型(及不同超参数组合)在验证集上的主要性能指标结果。 | 模型 | 超参数组合 | 验证集准确率 | 验证集F1分数 | 备注 | | :--------------- | :--------------- | :----------- | :----------- | :---------------- | | 逻辑回归 | C=1.0, penalty=l2| 0.782 | 0.761 | 基线模型 | | 随机森林 | n_estimators=200 | 0.821 | 0.803 | | | XGBoost | learning_rate=0.1| 845 | 832 | 表现最佳 | | 简单三层神经网络 | ... | 0.812 | 0.798 | 训练时间较长 |
分析与决策: 基于实验结果,分析各模型优缺点(性能、训练速度、可解释性、复杂度),并阐述最终选择某个模型及其最优超参数组合的理由。“尽管XGBoost与神经网络性能接近,但XGBoost训练速度更快且模型更轻量,满足实时性要求,故选用XGBoost,其最优参数为learning_rate=0.1, max_depth=6, n_estimators=200。”
第四步:模型训练与评估(验证成效) 在选定最优配置后,进行最终训练与严格测试:
- 最终训练: 使用完整训练集(或结合验证集)和确定的最优超参数,训练最终模型,记录使用的硬件资源(如GPU型号)、训练时长、最终模型文件大小等信息。
- 测试集评估: 在从未参与训练或调优的独立测试集上进行严格评估,报告所有预先定义的评估指标结果。这是衡量模型泛化能力的黄金标准。
- 深入分析: 超越单一指标:
- 混淆矩阵: 分析具体错误类型(如分类问题中的假阳性、假阴性)。
- 误差分析: 检查模型在哪些特定样本或数据子集上表现不佳?是否存在系统性偏差?(如对某类用户或场景预测效果差)。
- 可解释性: 尝试理解模型决策(如使用SHAP值、LIME),记录关键发现。
记录重点:突出测试集的独立性,详实报告各项评估指标结果,并包含对模型局限性和潜在偏差的客观分析。“模型在测试集上F1分数为0.84,略低于验证集结果,表明存在一定过拟合;误差分析发现模型对包含网络新词的‘中性’评论易误判为‘消极’。”
第五步:部署与监控(投入应用) 模型构建的终点是创造价值:
- 部署方案: 简述模型如何集成到实际系统?(如封装为REST API、嵌入到应用程序),记录部署环境(云端、边缘设备?)、依赖库及版本。
- 监控机制: 上线后如何持续跟踪?
- 性能监控: 实时监测预测延迟、吞吐量、资源消耗。
- 效果监控: 定期评估模型在线上真实数据上的核心指标(如准确率、AUC)是否发生显著衰减(概念漂移)。
- 数据监控: 监控输入数据的分布是否与训练数据相比发生重大变化(数据漂移)。
- 回滚与更新计划: 制定模型性能下降时的回滚策略,以及模型迭代更新的触发条件和流程。
记录重点:说明模型如何服务于业务,并强调持续监控的重要性及具体监控指标,体现模型的长期维护策略。
贯穿始终:版本控制与文档规范
- 代码与数据版本化: 使用Git等工具严格管理代码、配置文件和数据处理脚本,记录关键依赖库的精确版本号,对使用的数据集进行版本标识(如MD5校验和、唯一版本号)。
- 文档即代码: 将模型构建过程文档(如README.md)与代码一同纳入版本控制,使用清晰的结构(如上述步骤)、规范的命名、必要的图表进行阐述,保持文档的持续更新。
清晰的AI模型构建文档远非形式主义,它是项目成功的路线图、团队协作的通用语、知识传承的载体以及模型合规与可信度的基石,从定义目标到部署监控,每一步的细致记录都让模型生命周期的管理更加严谨高效,优秀的模型构建者,必然是优秀的记录者——正是这份对过程的尊重,才让冰冷的算法真正释放出解决现实问题的智慧力量。

 13888888888
13888888888

 点击咨询
点击咨询 