如何高效为AI导入模型文件:实用指南
在人工智能应用开发中,模型文件如同引擎的心脏,掌握正确的模型导入方法,是释放AI潜力的关键第一步,无论你使用的是PyTorch、TensorFlow还是其他框架,理解模型文件的本质与加载流程至关重要。
理解模型文件的核心 模型文件本质上是训练后神经网络结构的保存形态,包含:
- 网络架构:层结构、连接方式、激活函数
- 训练权重:模型从数据中学到的核心参数
- 元数据:训练配置、版本、输入输出规范等 常见格式包括:
- PyTorch (.pth, .pt):使用
torch.save()保存模型状态字典或完整模型 - TensorFlow/Keras (.h5, .keras, SavedModel目录):标准Keras格式或更灵活的SavedModel
- ONNX (.onnx):开放神经网络交换格式,支持跨框架互操作
- 其他框架专用格式:如Scikit-learn的.pkl
主流框架模型导入实战
PyTorch:简洁灵活
import torch import torchvision.models as models # 方法1:加载状态字典(需预定义模型结构) model = models.resnet50(pretrained=False) # 创建空白模型结构 state_dict = torch.load('resnet50_weights.pth') # 加载保存的权重 model.load_state_dict(state_dict) # 将权重加载到模型中 model.eval() # 设置为评估模式 # 方法2:加载完整模型(包含结构和权重) model = torch.load('full_resnet50_model.pt') model.eval()- 关键点:确保加载环境与保存环境的PyTorch版本、CUDA版本兼容。
model.eval()对包含Dropout、BatchNorm等层的模型必不可少。
- 关键点:确保加载环境与保存环境的PyTorch版本、CUDA版本兼容。
TensorFlow/Keras:多样选择
import tensorflow as tf # 方法1:加载.h5/.keras文件(标准Keras模型) model = tf.keras.models.load_model('my_keras_model.h5') # 方法2:加载SavedModel格式(目录形式,推荐) model = tf.keras.models.load_model('path/to/saved_model_directory') # 方法3:仅加载权重(需先有相同结构模型) model = tf.keras.applications.ResNet50(weights=None) # 创建无权重模型 model.load_weights('resnet50_weights.h5') # 加载权重文件- 关键点:SavedModel是TensorFlow 2.x推荐格式,包含完整计算图和元数据,兼容性更好。
Hugging Face Transformers:预训练模型库
from transformers import AutoModelForSequenceClassification, AutoTokenizer # 指定模型名称或本地路径 model_name = "bert-base-uncased" # 或本地路径 './my_local_bert/' model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)
- 关键点:库自动处理下载(首次)和加载,支持大量预训练模型,指定
local_files_only=True可强制使用本地文件。
- 关键点:库自动处理下载(首次)和加载,支持大量预训练模型,指定
ONNX:跨框架桥梁
import onnxruntime as ort # 创建ONNX Runtime推理会话 session = ort.InferenceSession("model.onnx") # 获取输入输出名称 input_name = session.get_inputs()[0].name output_name = session.get_outputs()[0].name # 准备输入数据(需符合模型要求) import numpy as np input_data = np.array(...) # 根据模型输入shape和类型构造数据 # 运行推理 results = session.run([output_name], {input_name: input_data})- 关键点:ONNX模型主要用于跨平台推理,加载后通过
InferenceSession进行预测,通常不再进行训练。
- 关键点:ONNX模型主要用于跨平台推理,加载后通过
关键注意事项与常见问题解决
环境一致性:模型保存与加载环境(Python版本、框架主/次版本、CUDA/cuDNN)差异是主要错误来源,利用虚拟环境或容器技术(如Docker)可最大限度保证一致性。
设备映射 (GPU/CPU):
# PyTorch 指定加载设备 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = model.to(device) # 或在加载时指定map_location state_dict = torch.load('model.pth', map_location=device) # TensorFlow 通常自动处理,也可在加载前设置 tf.config.set_visible_devices([...], 'GPU') # 或 'CPU'自定义层/对象:模型包含非标准层或自定义代码时,加载前必须确保该代码定义可用,在PyTorch中定义相同类;在TensorFlow中使用
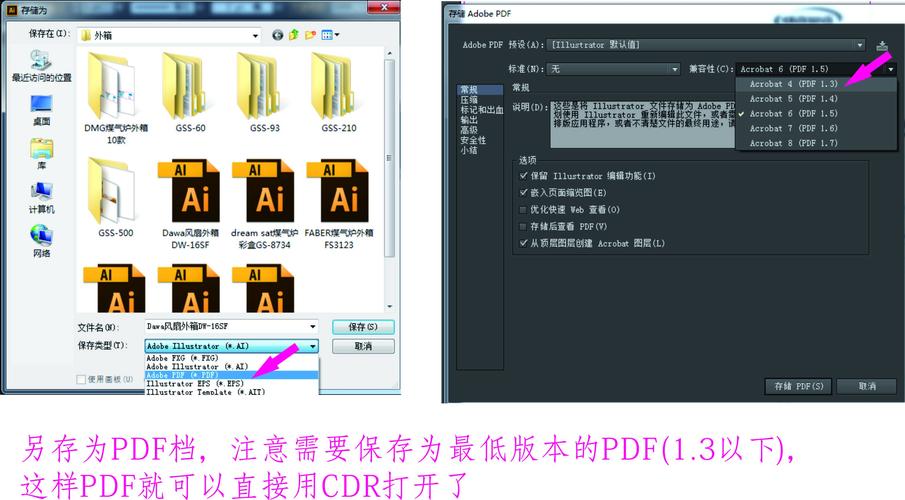
custom_objects参数:model = tf.keras.models.load_model('custom_model.h5', custom_objects={'MyCustomLayer': MyCustomLayer})文件路径与权限:确保程序有权限访问模型文件路径,使用绝对路径更可靠。
模型验证:加载后,务必进行简单推理测试(如输入样本数据),验证输出是否符合预期。
安全警告:谨慎加载来源不明的模型文件,存在恶意代码风险,仅使用可信来源的模型。
大模型加载:对于超大模型,考虑分片加载、内存映射或使用
accelerate等库优化资源占用。版本陷阱:框架更新可能导致旧版模型无法加载,关注官方文档的向后兼容性说明,必要时尝试保存/导出为更新的格式。
利用工具简化流程
- 模型转换工具:如
torch.onnx.export(PyTorch转ONNX)、TensorFlow的转换工具、onnxruntime等,解决框架间互操作问题。 - 模型管理平台:MLflow、Weights & Biases等平台提供模型注册、版本控制和部署功能。
- 云服务集成:AWS SageMaker、Azure ML、GCP Vertex AI等平台简化了模型部署和调用流程。
熟练掌握模型加载如同拥有了开启AI大门的钥匙,实践是核心——多尝试不同格式和框架,遇到错误时查阅官方文档和社区讨论,随着AI技术的迭代,新工具与格式会不断涌现,持续探索才能保持优势,祝你成功驾驭模型,让智能应用高效落地!

 13888888888
13888888888

 点击咨询
点击咨询 