AI大模型的学习之道:从人类智慧中汲取灵感
想象一个拥有海量知识却不知如何运用的天才——这正是初生AI大模型的真实写照,它们的学习过程并非魔法,而是一场融合了人类教育智慧与前沿技术的精密工程,理解其学习机制,能让我们更理性地看待其能力边界与发展潜力。
基础构建:从“通识教育”到“专业深造”
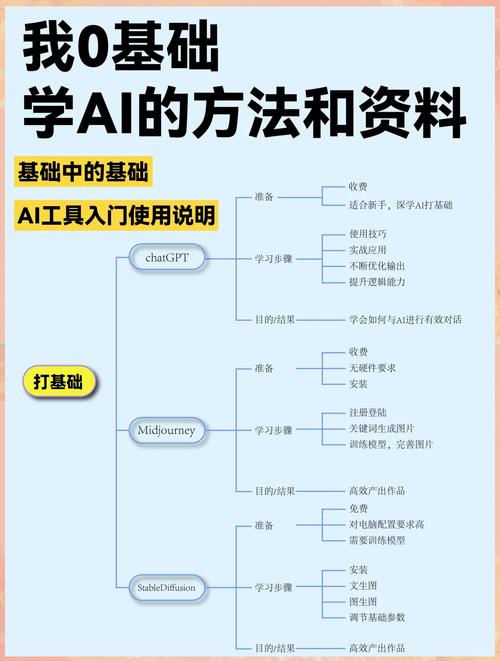
如同人类学习始于广泛认知,大模型的核心能力源于预训练阶段,这一过程如同为其构建底层知识图谱:
- 海量数据输入:模型“阅读”万亿级别的文本、代码等多模态信息,学习语言规则、基础事实与世界关联。
- 自监督学习:通过预测句子中被遮蔽的词、推测下一句内容等方式,模型自主挖掘数据中的统计规律与语义关联。
- 构建通用表征:最终形成对词语、概念及其复杂关系的深度理解,奠定后续专业能力的根基。
预训练模型仅是“博学”,未必“专精”。微调阶段如同专业教育:

- 指令微调:使用精心设计的指令-答案对,教会模型理解并遵循人类意图。
- 人类反馈强化学习:引入人类对模型输出的偏好评价,使其持续优化表达方式、提升生成结果的有用性与安全性,实现“精益求精”。
- 领域适配:注入特定领域数据(如医疗文献、法律条文),可显著提升模型在专业任务上的表现。
核心技术:Transformer架构的“思维引擎”
驱动这场高效学习的核心,是Transformer架构,其核心优势在于:
- 注意力机制:模型能动态聚焦当前任务中最相关的信息片段,高效处理长距离依赖关系,这如同人类在复杂任务中自动忽略干扰、抓住重点。
- 并行计算能力:可同时处理序列中所有元素,极大提升了训练与推理效率,是处理海量数据的关键。
- 层次化表征:通过多层堆叠,模型逐步构建从基础语言特征到高级语义概念的抽象表示,形成深度理解。
关键挑战与优化方向
构建高效、可靠的大模型学习系统,面临多重挑战:
- 算力与能耗:训练万亿参数模型需数千GPU集群运行数月,能耗巨大,优化算法效率、探索稀疏模型等是重要方向。
- 数据质量与偏见:模型能力高度依赖训练数据,数据中的噪声、错误或社会偏见会被模型吸收并放大,严格的数据清洗、去偏技术至关重要。
- 灾难性遗忘:在微调或学习新知识时,模型可能丢失先前掌握的重要信息,持续学习技术是解决这一难题的关键。
- 可解释性与可控性:理解模型内部决策逻辑、确保其行为安全可靠,是当前研究的核心难点。
未来之路:更高效、更可信的学习范式
大模型学习技术正朝着更智能、更集约的方向演进:
- 模型高效学习:如参数高效微调技术,仅更新少量参数即可适配新任务,大幅降低成本。
- 持续学习与记忆增强:探索类脑机制,使模型能像人类一样持续积累知识而不遗忘,并具备事实检索能力。
- 多模态融合学习:整合文本、图像、声音、视频等信息,构建更接近人类的多模态世界认知模型。
- 对齐与价值观学习:确保模型目标与人类价值观深度一致,在技术应用中嵌入伦理考量。
AI大模型的进步始终服务于拓展人类认知边界、解决复杂问题,其学习能力越接近人类灵活性与效率,我们越需重视技术发展中的伦理框架与社会共识构建,每一次算法的优化,都应伴随着对应用场景的审慎思考——这或许是我们从AI学习过程中获得的最重要启示。

 13888888888
13888888888

 点击咨询
点击咨询 