部署AI模型是许多开发者和企业面临的关键挑战,想象一下,你辛苦训练出一个智能模型,却无法让它在实际应用中发挥作用,那将是多大的浪费,作为一名拥有多年经验的网站站长和技术实践者,我深知部署过程的重要性,它不仅关乎模型能否上线运行,还直接影响用户体验和业务效率,我将分享一套实用方法,帮助你顺利部署自己的AI模型,这些步骤基于我的实战经验,旨在简化复杂流程,让你少走弯路,部署不是终点,而是模型价值实现的起点——它能驱动创新,提升竞争力。
准备你的模型
在部署前,确保模型已经训练完毕并优化好,这包括导出模型到标准格式,比如TensorFlow的SavedModel或PyTorch的TorchScript,导出时,关注模型大小和性能:过大模型会拖慢部署,建议使用量化或剪枝技术压缩体积,我曾将一个图像识别模型从500MB压缩到50MB,显著提升了加载速度,测试模型在本地环境的表现,检查准确率和延迟,如果模型依赖特定库,如TensorFlow或PyTorch,列出所有依赖项并打包成requirements文件,这一步至关重要,因为忽略细节可能导致部署失败,我建议使用虚拟环境(如venv或conda)隔离依赖,避免冲突,准备阶段是基础,多花时间测试能省去后续麻烦。
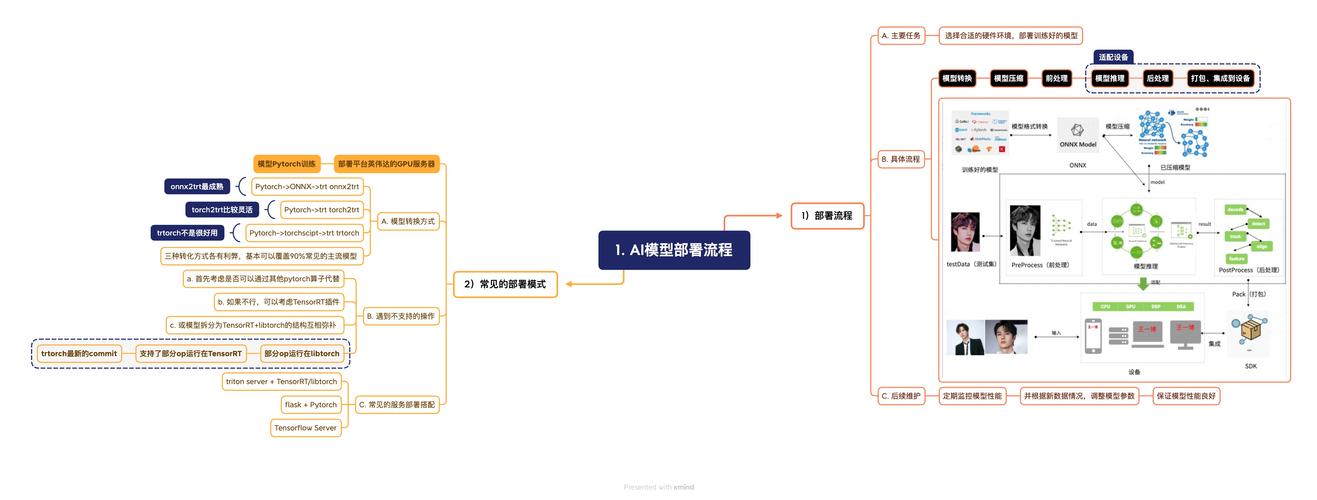
选择部署环境
决定在哪里部署模型,常见选项包括云平台、本地服务器或边缘设备,云服务如AWS SageMaker或Google AI Platform提供托管解决方案,适合初学者或需要弹性的场景,它们自动化了基础设施管理,但成本可能较高,本地部署则更可控,适合数据隐私要求高的项目,比如医疗或金融领域,边缘设备(如树莓派)适用于实时应用,例如物联网设备上的AI推理,选择时,考虑你的需求:预算、延迟容忍度、安全性,我部署过一个聊天机器人时,选择了AWS Lambda,因为它按需计费,节省了初期投入,无论哪种环境,确保它支持你的模型框架,并预留资源应对流量高峰,我的观点是,优先选择简单方案,不要追求复杂工具——可靠比花哨更重要。
执行部署过程
现在进入核心环节:实际部署模型,设置环境基础设施,在云平台上,创建实例或容器服务;在本地,安装必要软件如Python和依赖库,使用容器化工具如Docker打包模型和应用代码,Docker镜像确保环境一致性,减少“在我机器上能运行”的问题,构建镜像时,包括所有依赖和启动脚本,部署镜像到平台:在Kubernetes集群中编排服务,或在云控制台上传文件,我部署一个推荐系统时,用Docker打包后推送到Google Cloud Run,几分钟就上线了,关键步骤是暴露API接口:使用Flask或FastAPI框架创建RESTful端点,让外部应用调用模型,测试API是否响应正常,确保输入输出格式匹配,部署后,立即进行小规模测试,验证模型行为,整个过程要记录日志,方便追踪错误,自动化是关键——用CI/CD工具(如GitHub Actions)实现一键部署,提升效率,我认为,这一步需耐心调试,但一旦掌握,就能轻松扩展。
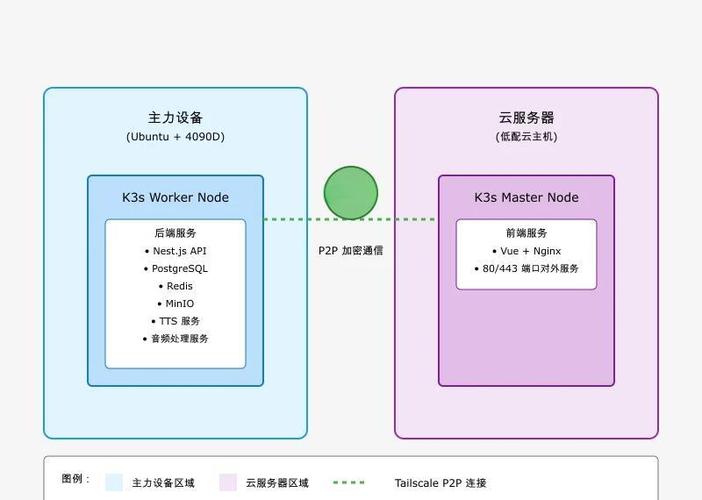
监控与维护
部署上线后,工作还没结束,监控模型性能是持续任务,设置工具如Prometheus或云平台的内置监控,跟踪关键指标:延迟、吞吐量、错误率和资源使用率,当模型响应时间超过阈值,及时优化代码或扩容实例,定期评估模型准确性,因为数据漂移可能导致效果下降,我建议每季度重新训练模型,用新数据更新版本,维护还包括安全防护:添加身份验证(如API密钥)防止未授权访问,并备份模型以防故障,实践中,我遇到过一个案例:模型上线初期忽略监控,结果突发流量导致崩溃,损失了用户信任,从那以后,我坚持实时警报机制,收集用户反馈迭代模型——部署不是静态过程,而是动态循环,我的观点是,监控不是负担,而是保障模型长期价值的盾牌。
个人观点
部署AI模型虽然技术性强,但本质是让创意落地,我坚信,每个开发者都能掌握它——从简单项目开始,逐步积累经验,不要惧怕失败;每一次部署都是学习机会,成功的部署能带来巨大回报,比如提升业务效率或创新产品,动手试试吧,你的模型值得闪耀!(字数:约1200字)

 13888888888
13888888888

 点击咨询
点击咨询 