如何从零开始构建属于你的AI模型:一份实战指南
在人工智能浪潮席卷全球的今天,创建专属AI模型不再是顶尖实验室的专利,无论你是创业者、开发者还是技术爱好者,掌握这项技能都将开启无限可能,下面是一份清晰的实战路径:
第一阶段:明确目标与知识储备
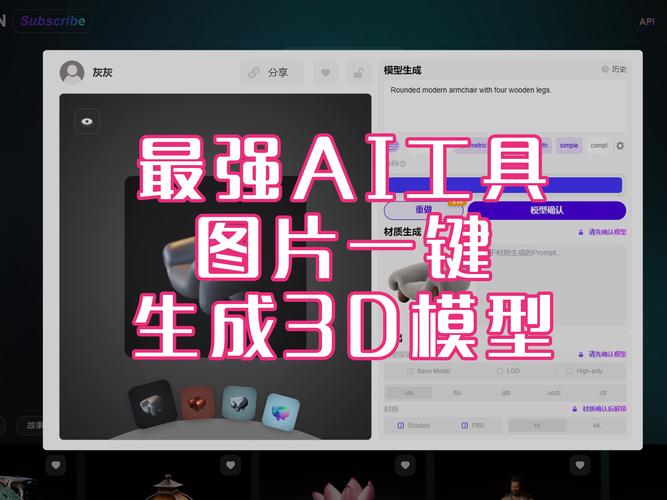
- 精准定义问题: 你的模型要解决什么?图像识别?文本生成?销售预测?具体目标决定技术路线(如CNN处理图像,Transformer处理语言)。
- 掌握核心基础:
- 编程: Python是首选,精通NumPy、Pandas库。
- 数学: 线性代数、微积分、概率论是理解模型运作的基石。
- 机器学习概念: 深入理解监督/无监督学习、过拟合、损失函数、梯度下降等核心原理。
第二阶段:数据 - 模型的基石
- 收集高质量数据: 数据质量直接影响模型上限,确保数据相关性强、覆盖面广(如构建猫狗识别器,需包含不同品种、姿态、光照的图片)。
- 严格清洗与预处理:
- 剔除错误、重复样本
- 处理缺失值(填充或删除)
- 统一格式(如图像尺寸归一化、文本分词)
- 关键步骤:划分训练集(70%)、验证集(15%)、测试集(15%)
第三阶段:模型开发实战

- 框架选择:
- PyTorch: 研究首选,动态计算图灵活直观
- TensorFlow/Keras: 生产部署成熟,尤其适合大型系统
- Hugging Face Transformers(NLP): 预训练模型库丰富
- 模型架构决策:
- 经典模型复用: 图像识别用ResNet,文本处理用BERT/GPT,快速高效
- 自定义构建: 使用框架层(如Keras Layers, PyTorch nn.Module)从头搭建
- 训练过程详解:
- 设置超参数: 学习率(0.001常见起点)、批次大小(32/64/128)、训练轮次(epoch)
- 选择优化器: Adam通常表现稳健
- 监控与调试: 紧盯训练/验证损失及准确率,防止过拟合(早停、Dropout、正则化)
第四阶段:模型评估与优化
- 严谨测试: 在从未见过的测试集上评估指标(准确率、精确率、召回率、F1分数、AUC等)。
- 深度优化策略:
- 超参数调优: 利用工具如Optuna、Ray Tune自动搜索最佳组合
- 模型压缩: 知识蒸馏、剪枝技术提升移动端效率
- 集成学习: 融合多个模型预测提升鲁棒性
第五阶段:部署与应用
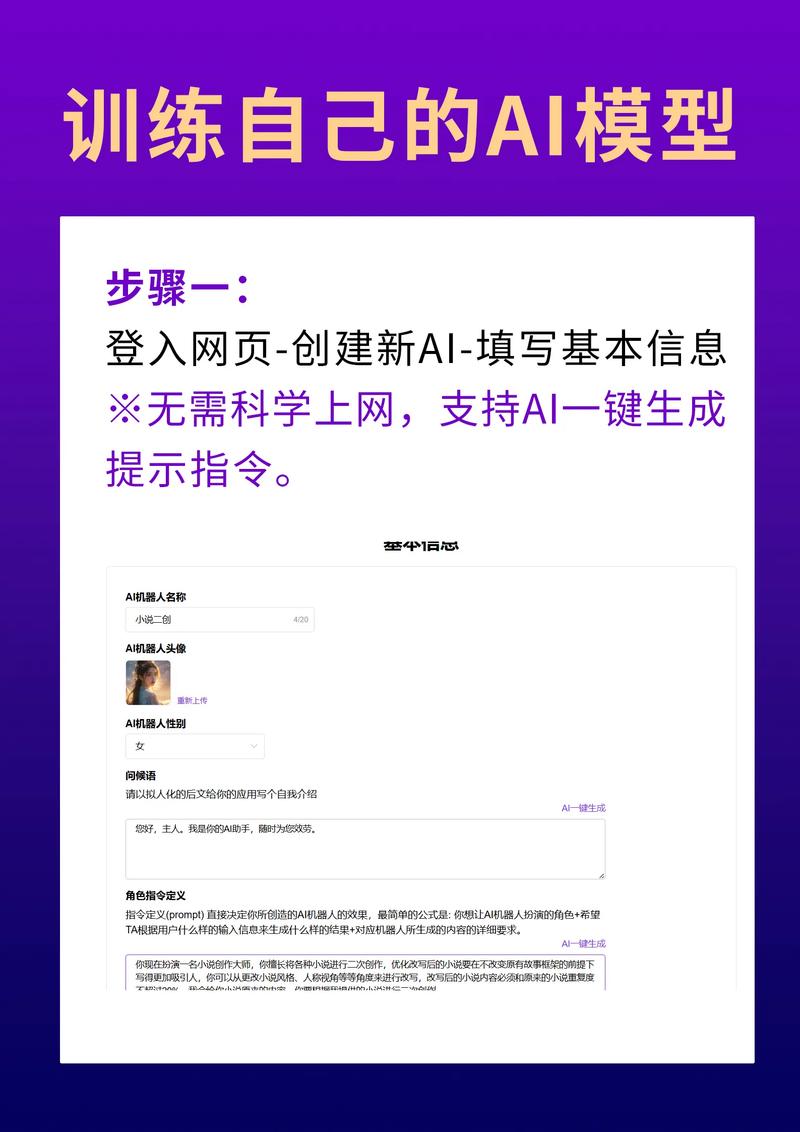
- 部署选项:
- 云服务: AWS SageMaker、Google AI Platform、Azure ML 提供全托管方案
- 本地服务器: Docker容器化部署保证环境一致性
- 边缘设备: TensorFlow Lite、ONNX Runtime 优化移动端/IoT运行
- 构建API接口: 使用 Flask、FastAPI 封装模型,实现远程调用
- 持续监控: 追踪线上预测性能、数据漂移,建立模型更新机制
关键挑战与应对:
- 数据瓶颈: 利用数据增强(旋转/裁剪图像)、迁移学习(ImageNet预训练)、合成数据(GANs)破解小数据困局
- 算力限制: 优先使用Google Colab免费GPU,或按需采购云算力(AWS EC2 G4实例)
- 伦理与责任: 严格审查数据偏见,保护用户隐私,建立模型决策可解释机制
实用工具箱推荐:
- 数据管理: LabelImg(图像标注),Prodigy(高效标注)
- 开发环境: Jupyter Notebook, VS Code + Python插件
- 版本控制: DVC(数据版本),MLflow(实验追踪)
- 部署监控: Prometheus + Grafana 性能看板
构建AI模型是一场融合技术、耐心和创造力的旅程,初期建议从Kaggle经典竞赛(如泰坦尼克生存预测)入手,逐步挑战更复杂项目,随着大模型技术发展,基于LLaMA、Stable Diffusion等开源基座进行微调,已成为快速构建行业应用的高效路径,关键在于动手实践——从第一行代码开始,你的AI探索之路就已启程,真正的竞争力源于将技术深度融入垂直场景,解决真实世界痛点。

 13888888888
13888888888

 点击咨询
点击咨询 