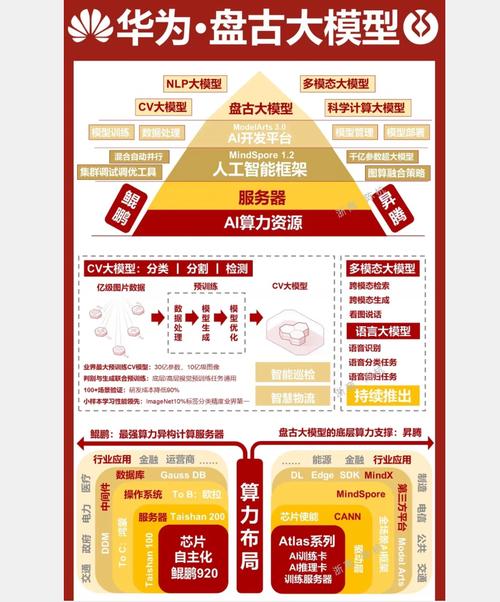
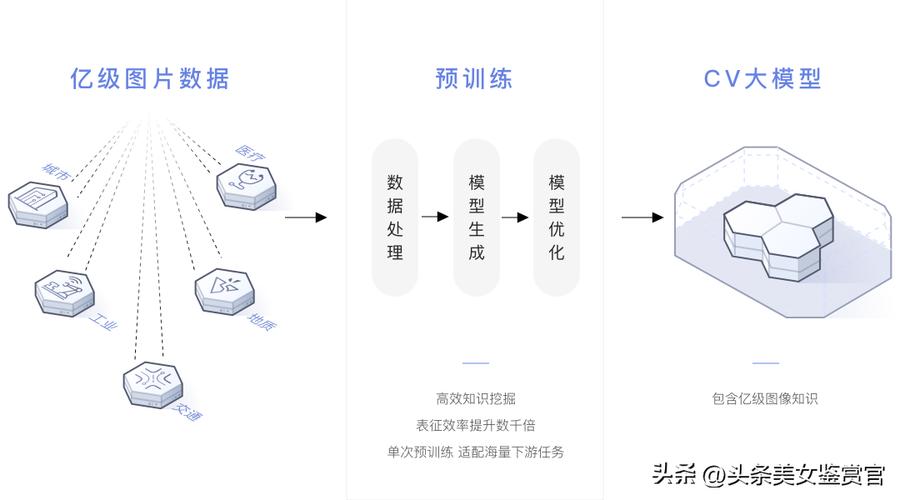
盘古AI大模型升级指南:权威解读与实操建议
某大型金融机构接入盘古大模型初期,客服响应效率提升30%,三个月后,随着业务量激增与复杂咨询涌现,模型响应速度下降15%,准确率波动明显,技术团队启动升级流程后,不仅处理速度恢复至原有水平,复杂金融产品咨询的解析准确率更跃升22个百分点,这个案例清晰揭示:盘古AI大模型的竞争力,根植于持续、精准的升级策略。
为何升级是盘古AI持续领先的核心引擎
- 性能跃迁: 升级直接关联模型核心能力——更精准的语义理解、更广的知识覆盖、更优的推理能力,新版本通常在基准测试中展现显著提升。
- 场景适配进化: 业务需求动态变化,升级使模型更好适应新任务(如特定行业术语理解、新型数据分析),保持解决方案前沿性。
- 安全与合规加固: 持续升级修补潜在漏洞,强化内容过滤与伦理对齐,确保应用符合日益严格的法规要求。
- 效率与成本优化: 优化后的模型架构与算法常带来计算资源消耗降低,推理速度提升,直接转化为运营成本节约。
盘古AI大模型升级的核心技术路径
模型架构深度优化
- 参数高效微调 (PEFT): 应用LoRA、Adapter等技术,以极低资源消耗注入新知识或调整模型行为,避免全参数训练的高成本。
- 知识蒸馏与压缩: 将大型教师模型精华“蒸馏”至更轻量学生模型,保持高性能同时降低部署门槛。
- 混合专家系统 (MoE): 探索路由机制,动态激活处理特定任务的专家子网络,大幅提升模型容量与效率。
数据驱动的能力飞跃
- 高质量数据持续注入: 引入清洗后的行业语料、最新知识库、多语言数据,显著扩展认知边界与专业性。
- 强化学习对齐优化 (RLHF/RLAIF): 依据人类反馈或AI生成反馈,精细调整模型输出,确保更安全、有用、符合预期。
- 合成数据创新应用: 在数据受限领域,利用模型生成高质量合成数据辅助训练,突破瓶颈。
基础设施与部署协同进化

- 混合精度训练加速: 应用FP16、BF16等精度策略,大幅缩短训练周期,提升迭代速度。
- 硬件深度适配: 针对昇腾等国产算力平台进行内核级优化,释放极致性能。
- 云原生弹性部署: 采用容器化、Kubernetes编排,实现模型版本无缝切换、资源弹性伸缩与高效推理服务。
企业实施盘古AI升级的实践路线图
精准评估与目标定义
- 现状诊断: 全面分析现有模型性能瓶颈(响应延迟、错误类型、资源消耗)。
- 需求聚焦: 明确升级核心目标(如提升特定任务准确率20%、降低推理延迟50%、满足新合规条款)。
- 版本选型: 深入研究华为官方发布的升级日志、技术白皮书,选择最能匹配目标的基础版本。
周密准备与环境构建
- 数据引擎: 严格收集、清洗、标注与目标强相关的高质量数据集。
- 算力保障: 评估所需算力资源(GPU/NPU集群、内存、存储),搭建或确认训练/推理环境。
- 技术栈统一: 确保团队掌握微调框架(如MindSpore, PEFT库)、部署工具链。
高效执行与迭代验证
- 分阶段验证: 先在隔离环境小规模验证升级效果(如使用测试数据集),再逐步扩大范围。
- A/B测试驱动决策: 线上并行运行新旧版本,以核心业务指标(转化率、满意度、处理时长)作为升级依据。
- 监控与回滚: 部署严密监控(性能、异常、资源),预设快速回滚机制保障业务连续性。
安全合规与伦理贯穿始终
- 升级同步加固: 将最新的安全补丁、内容过滤规则、隐私保护技术整合入升级流程。
- 全面测试: 升级后必须进行严格的安全渗透测试、偏见审计、合规性检查。
- 文档与审计留痕: 详尽记录升级过程、决策依据、测试结果,满足内外部审计要求。
升级中的关键挑战与应对智慧
- 兼容性风险: 新版本API或输出格式变化可能导致下游应用中断。对策: 详读官方变更说明,预留充足适配测试时间,使用兼容层/封装接口。
- 数据依赖与质量陷阱: 升级效果高度依赖新数据质量。对策: 建立严格数据治理流程,引入数据验证模块,优先使用权威来源数据。
- 成本效益平衡: 频繁升级带来资源消耗。对策: 建立科学的升级评估模型,优先选择高ROI(投资回报率)的升级点,利用PEFT等技术降低成本。
- 人才技能储备: 大模型升级需要专业AI工程能力。对策: 与华为技术团队/认证伙伴深度合作,投资内部团队技术培训。
技术升级从来不是简单的版本替换,而是战略能力的前瞻性布局,每一次对盘古AI模型的深度优化,都是在重构智能应用的效率边界与可能性空间,当企业将模型迭代内化为核心运营机制,便能在算法驱动的竞争中持续掌握定义未来的主动权。 华为持续开放的升级路径与强大工具链,正降低这一进程的门槛,关键在于决策者能否超越工具视角,将AI进化深度融入业务基因。

 13888888888
13888888888

 点击咨询
点击咨询 