从零开始构建专属AI声音模型的实战指南
你是否曾想过拥有一个能惟妙惟肖模仿特定人声的AI助手?或是为创作注入独特的声音灵魂?AI声音模型技术正以前所未有的速度走进现实,本文将深入解析构建个性化AI声音模型的完整流程,即使是技术新手,也能循着清晰路径实现目标。
基石:高质量语音数据的精心准备

声音模型的优劣,核心在于训练数据的质量。
-
严选录音源:
- 对象明确: 确定你要克隆的目标声音,确保录音环境极其安静,避免背景杂音干扰。
- 设备精良: 使用专业麦克风(USB电容麦是基础)进行录制,智能手机录音仅作应急之选,音质损失显著。
- 内容规划: 录制覆盖广泛语音内容的素材:日常对话、情感表达、不同语速的朗读、特殊发音等,内容越丰富,模型表现越自然。
-
录音操作规范:
- 格式统一: 全程采用无损格式(WAV/PCM)录制,采样率推荐44.1kHz或48kHz,位深16bit。
- 距离恒定: 保持口与麦克风的稳定距离(约15-30厘米),防止音量波动过大。
- 情感注入: 朗读者需带入自然情感,避免机械式念稿,这对模型捕捉声音神韵至关重要。
-
数据清洗与切片:
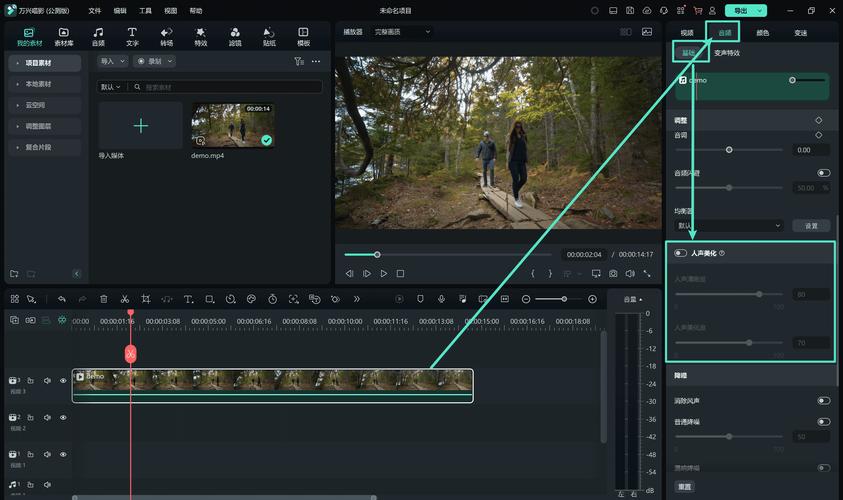
- 降噪处理: 利用Audacity、Adobe Audition等工具消除环境底噪、电流声等干扰。
- 精准切割: 将长录音分割成清晰、独立的短句(通常2-10秒),确保每段音频仅包含单一语音,无重叠人声或突兀声响。
- 格式转换: 最终将所有片段统一转换为模型训练所需的格式(如.wav)。
理想数据量: 纯净语音至少200分钟,数据越充足、越干净,模型拟真度上限越高。
核心:选择合适的模型架构与训练工具
技术门槛正迅速降低,开源力量功不可没。
-
主流技术路线:
- 端到端TTS: Tacotron系列及其变种(如Tacotron 2)是经典之选,输入文本直接输出原始音频波形(通过WaveNet等声码器)。
- 声码器: WaveNet、WaveGlow、HiFi-GAN等负责将模型生成的频谱(如梅尔频谱)转化为可听的声音波形,对音质影响巨大。
- 扩散模型: 如Grad-TTS、DiffWave等新兴力量,在生成自然度和鲁棒性上展现强大潜力。
- 端到端扩散: OpenAI的Voice Engine、微软的VALL-E等代表了前沿方向,效果惊艳但资源消耗极高。
-
开源工具推荐(2024年实用选择):
- TensorFlowTTS / ESPnet: 提供丰富、模块化的开源TTS实现方案,社区支持活跃,适合研究者及进阶开发者。
- Coqui TTS: 对用户极为友好,提供预训练模型与简易API,其XTTS模型支持少量样本微调,是快速上手的利器。
- So-VITS-SVC: 在声音转换领域表现突出,擅长基于目标音色转换歌声或语音,对中文支持良好。
- PaddleSpeech: 百度开源的一站式语音工具包,涵盖丰富TTS模型及训练脚本,中文文档完善。
工具选择建议: 新手推荐Coqui TTS(易用性高);追求更高定制化与效果可选TensorFlowTTS/ESPnet或PaddleSpeech;专注歌声克隆则考虑So-VITS-SVC。
实战:模型训练的关键步骤
准备好数据和工具后,进入核心训练阶段。
-
环境搭建:
- 配置高性能计算环境:强烈推荐使用NVIDIA GPU(显存建议≥8GB,越大越好)。
- 安装所选工具链要求的深度学习框架(PyTorch / TensorFlow)、CUDA/cuDNN驱动及Python依赖库。
-
数据预处理:
- 使用工具内置脚本将音频数据转换为训练所需的中间格式(通常是梅尔频谱图,一种声音特征的压缩视觉表示)。
- 生成对应的文本转录文件(.txt或.json),确保音频片段与文本内容精确对齐,工具通常提供强制对齐功能辅助完成。
-
配置训练参数:
- 精心调整超参数:学习率(Learning Rate)、批大小(Batch Size)、训练轮数(Epochs)等是重中之重,初始值可参考官方文档或社区经验。
- 配置模型架构细节:如嵌入维度、注意力机制类型、层数等(高级选项)。
-
启动训练与监控:
- 运行训练脚本,耐心等待,训练时间从数小时到数天不等,取决于数据量、模型复杂度及硬件性能。
- 实时监控训练日志(Loss值下降趋势)和TensorBoard等可视化工具,评估模型收敛情况,如遇Loss震荡或停滞,需调整参数或检查数据质量。
-
合成与初步测试:
- 使用训练好的模型(检查点)和配套声码器,输入文本生成试听音频。
- 仔细评估:发音准确度如何?音色相似度多高?语调是否自然流畅?是否存在机械感或杂音?
精雕细琢:模型优化与效果提升
首次训练往往难以尽善尽美,优化必不可少。
- 数据增广: 若效果欠佳,首要考虑补充更高质量、更多样化的语音数据,这是提升效果最根本的途径。
- 微调(Finetuning): 在已有较好基础模型(如预训练的通用TTS模型)上,用你的专属数据进行小规模再训练,通常能更快获得理想效果并节省资源。
- 参数调优: 基于测试结果,系统性地微调学习率、正则化强度等超参数,小步快跑,多次迭代验证。
- 声码器选择: 尝试不同的声码器(如HiFi-GAN通常比Griffin-Lim音质好得多),对最终声音的清晰度和自然度影响显著。
- 后处理技巧: 对合成音频进行适度的音量均衡、去除轻微嘶声等后期处理。
至关重要的伦理与法律考量
技术能力伴随重大责任:
- 明确授权: 必须获得声音提供者清晰、自愿的知情同意与授权,明确说明声音的用途范围和期限,未经许可克隆他人声音涉嫌严重侵权。
- 透明标识: 当使用AI生成的声音内容时,尤其在公开传播或商业场景下,应明确标注其为“AI合成语音”,避免误导公众。
- 防范滥用: 绝对禁止将技术用于制造虚假信息、欺诈、诽谤或其他非法目的,开发者与使用者均有责任维护技术应用的道德边界。
构建AI声音模型,既是严谨的技术工程,也是充满创造性的探索旅程。 从数据的耐心打磨到模型的迭代优化,每一步都影响着最终声音的灵魂,开源工具的蓬勃发展为个人和小团队打开了大门,但请始终牢记,强大的技术必须匹配同等的伦理意识与法律遵从,当你能清晰听到自己亲手训练的AI发出独特的声音时,那份成就感定会超越所有付出的辛劳,声音的未来,正由每一个负责任的实践者共同塑造。

 13888888888
13888888888

 点击咨询
点击咨询 