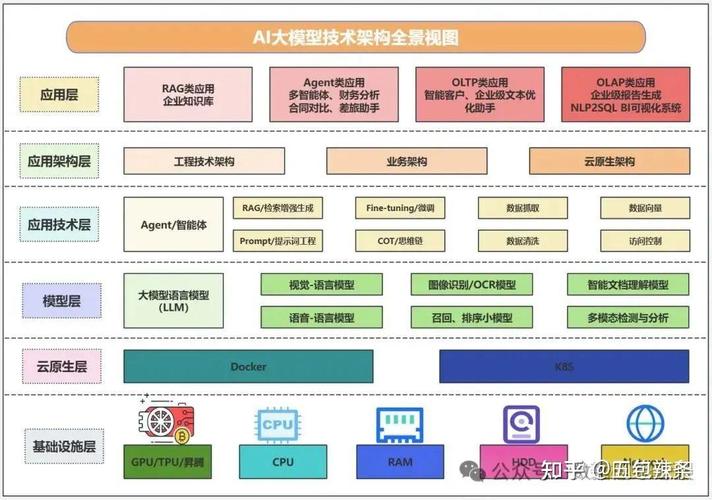
AI框架模型打包实战指南:让部署不再成为瓶颈
在实验室跑通的AI模型,到了生产环境却频频报错?不同框架间的模型迁移像在解谜题?模型打包正是解决这些痛点的关键技术,作为AI工程化的核心环节,掌握模型打包方法能大幅提升您的部署效率。
模型打包的本质与价值 模型打包是将训练完成的AI模型及其运行环境封装为标准化文件的过程,这解决了三大核心问题:
- 环境依赖隔离:将特定版本的Python库、系统依赖打包,避免“在我机器上能跑”的尴尬
- 跨平台部署:一次打包,可在Windows/Linux/macOS等多环境运行
- 保护知识产权:对模型架构和参数进行封装,降低核心算法泄露风险
主流打包工具链实战解析
PyInstaller方案(适合桌面端应用)
# 安装PyInstaller pip install pyinstaller # 打包入口脚本(包含模型加载和推理逻辑) pyinstaller --onefile --add-data "model.onnx;." inference_app.py
关键技巧:
- 使用
--add-data将模型文件嵌入可执行程序 - 通过
--hidden-import解决动态库缺失问题(如--hidden-import=sklearn.utils._weight_vector) - 输出单文件exe,用户双击即可运行
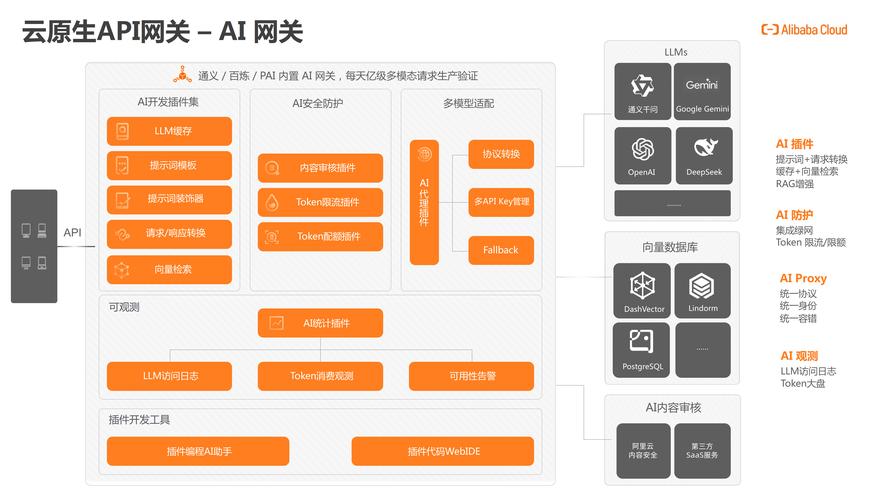
Docker容器化(企业级部署首选)
# Dockerfile示例 FROM python:3.9-slim COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY trained_model.pth /app/model/ COPY inference_api.py /app/ EXPOSE 5000 CMD ["python", "/app/inference_api.py"]
构建命令:docker build -t model-server:v1 .
运行命令:docker run -p 5000:5000 model-server:v1
最佳实践:
- 使用Alpine或Slim镜像减小体积(通常可压缩至300MB内)
- 设置非root用户运行增强安全性
- 通过环境变量注入配置(如
-e MODEL_PATH=/app/model)
ONNX通用格式转换(跨框架利器)
# PyTorch转ONNX示例
import torch.onnx
model = torch.load("resnet18.pth")
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, dummy_input, "resnet18.onnx",
opset_version=13,
input_names=["input"],
output_names=["output"])
注意事项:
- 检查算子支持列表(ONNX opset文档)
- 使用onnxruntime验证推理一致性
- 量化优化:
onnxruntime.quantization.quantize_dynamic()
避坑指南:打包中的典型雷区
- 依赖树爆炸:用
pip freeze > requirements.txt生成清单,通过pip-chill剔除非直接依赖 - CUDA版本冲突:在Dockerfile中固定基础镜像版本(如
nvidia/cuda:11.8.0-base) - 大模型加载慢:采用延迟加载技术,仅当API调用时实例化模型
- 安全加固:对序列化模型进行数字签名,防止篡改
行业趋势与选型建议 根据2023年MLOps社区调研:
- 78%的企业选择Docker+Kubernetes部署生产模型
- ONNX使用率年增长40%,成为跨框架标准
- WebAssembly(WASM)在边缘计算场景增速显著
个人建议初创团队从ONNX+FastAPI组合起步,快速验证业务逻辑;当面临复杂依赖时,果断采用Docker容器化;而对安全敏感的场景,可探索Enarx等机密计算方案,真正的工程价值不在于炫技,而在于构建用户无感知的稳定服务——当AI能力如水电般即开即用,技术创新才真正落地生根。

 13888888888
13888888888

 点击咨询
点击咨询 