近年来,人工智能技术逐渐深入日常生活,对话模型作为其中的重要应用,受到越来越多人的关注,许多开发者和技术爱好者希望能在本地环境中训练自己的AI对话模型,以满足特定需求或提升数据隐私保护,本文将介绍训练本地AI对话模型的基本流程与关键要点,帮助读者初步掌握这一技术。
训练一个本地AI对话模型,首要步骤是明确目标和需求,不同的应用场景需要不同的模型架构和训练数据,客服机器人需要大量行业相关对话数据,而娱乐型聊天机器人则可能需要更开放、多样化的语料,明确目标后,便可进入数据准备阶段。

高质量的数据是模型成功的基础,需收集与目标场景相关的文本数据,并进行清洗与预处理,数据清洗包括去除无关字符、纠正拼写错误、过滤低质量内容等,预处理则涉及分词、标注等自然语言处理常用方法,若数据量不足,可通过数据增强技术,如同义词替换、句式变换等方式扩充数据集。
接下来是模型选择,目前常用的对话模型包括基于循环神经网络(RNN)、长短期记忆网络(LSTM)、Transformer等架构的模型,Transformer架构因其强大的并行计算能力和长距离依赖捕捉能力,成为当前主流选择,GPT、BERT等预训练模型均基于Transformer,可通过微调适配特定任务。
选定模型后,需配置训练环境,本地训练通常需要较高的计算资源,尤其是GPU支持,建议使用如TensorFlow、PyTorch等深度学习框架,并安装相应依赖库,环境配置完成后,将预处理后的数据输入模型进行训练。
训练过程中,超参数调优尤为重要,学习率、批次大小、训练轮数等参数直接影响模型性能,初始阶段可参考已有研究的推荐设置,再通过多次实验调整,使用验证集监控模型表现,防止过拟合,若发现验证集性能下降,可提前停止训练或引入正则化技术。
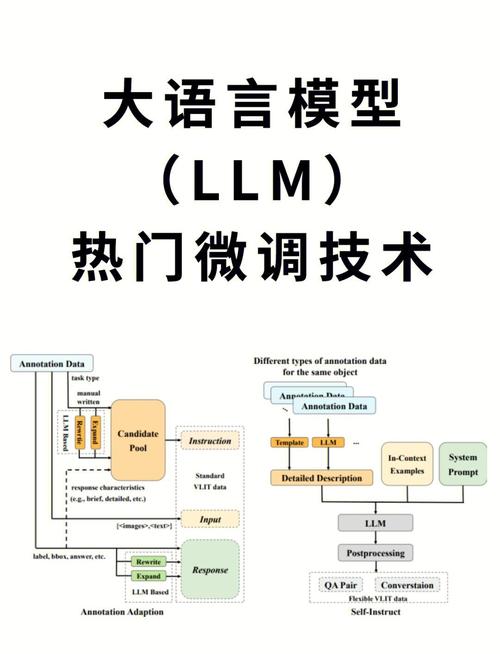
模型评估是训练完成后不可或缺的环节,除了常见的准确率、困惑度等指标,还可通过人工评估判断生成内容的质量是否自然、相关,这一环节有助于发现模型潜在问题,并指导后续优化。
训练本地AI对话模型虽具挑战,但也能带来显著收益,本地部署可有效保护数据隐私,避免敏感信息外泄,自定义模型能更精准契合特定业务需求,提升用户体验。
从技术角度看,成功训练对话模型离不开持续学习与实验,行业技术迭代迅速,新的模型架构与训练方法不断涌现,保持对前沿动态的关注,积极参与开源社区,将有助于提升模型效果与应用能力。
人工智能的本质是服务于人,对话模型的训练亦不例外,无论是为了提升工作效率,还是探索技术可能性,每一步实践都是对未来可能性的尝试,技术的价值,最终体现在如何更好地理解与响应人的需求。

 13888888888
13888888888

 点击咨询
点击咨询 