在数字化浪潮席卷各行各业的今天,人工智能技术已不再遥不可及,许多个人开发者、中小企业甚至技术爱好者都开始关注如何将强大的AI能力内化,在自己的计算环境中运行,这种将AI模型部署在本地硬件上的做法,不仅能更好地保障数据隐私,也能实现离线环境下的稳定应用,带来更可控、更灵活的使用体验。
开始本地部署之前,首要任务是评估并准备好你的硬件环境,虽然部分轻量级模型可以在消费级电脑上运行,但若要处理更复杂的任务(如大语言模型推理或图像生成),一块性能良好的GPU(图形处理器)将极大提升体验,显存大小直接决定了你能运行何种规模的模型,通常建议不少于8GB,充足的内存(建议32GB或以上)和高速固态硬盘也会显著减少模型加载与数据处理的时间。
准备好硬件后,下一步是选择适合的模型,开源社区提供了丰富的预训练模型资源,例如Hugging Face平台就聚集了来自全球开发者分享的众多模型,选择时需权衡模型能力与硬件限制:模型参数越多,能力通常越强,但对资源的要求也更高,对于入门用户,可从一些优化后的轻量模型入手,如经过剪枝或量化的版本,它们能在保留大部分性能的前提下显著降低资源消耗。
部署环节的核心是选择正确的工具与框架,目前主流的方式是使用专门的应用或库来简化流程,Ollama 是一款支持在本地运行大型语言模型的工具,它提供了简单的命令行界面,让模型拉取、加载和交互变得非常直观,对于习惯图形界面的用户,LM Studio 则提供了一个易于上手的桌面应用,能自动处理大部分技术细节,让你能像安装普通软件一样管理AI模型。
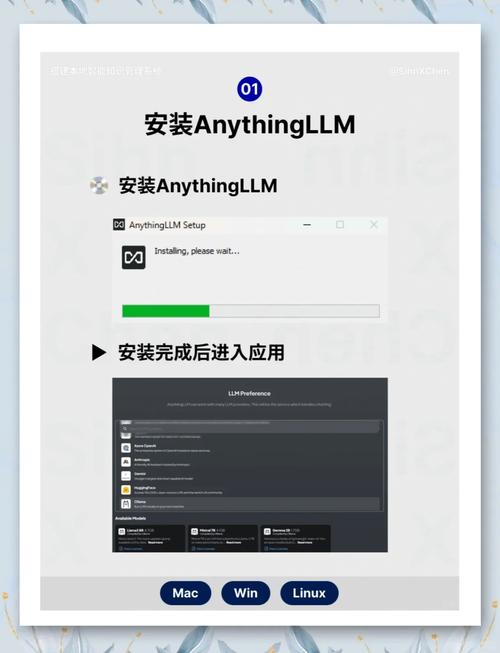
安装选定的工具后,通常只需几条命令或几次点击即可下载看中的模型,这个过程可能需要一些时间,取决于模型大小和网络环境,完成后,你就可以在本地与模型进行交互了:可能是通过命令行输入指令,也可能是在打开的窗口中直接提问,这种即刻的反馈体验,正是本地部署的魅力所在。
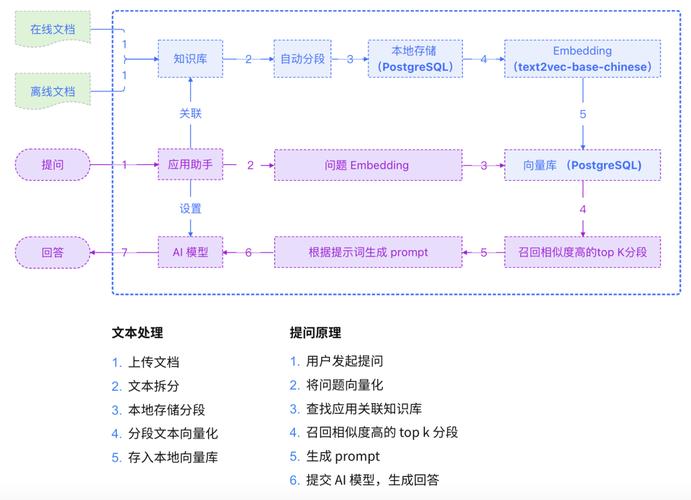
将模型成功运行起来后,你可能会考虑如何将其集成到自己的项目或工作流中,许多工具都提供了API接口,允许其他程序通过网络请求来调用本地模型的能力,这意味着你可以在自己编写的应用程序、自动化脚本甚至网站中嵌入AI功能,而所有数据处理都在本地完成,无需担忧数据泄露的风险。

这条探索之路并非总是平坦的,你可能遇到环境配置冲突、依赖库版本不兼容或显存不足导致运行失败的情况,耐心查阅文档、寻求社区帮助或是尝试不同的模型版本都是有效的解决途径,每一个问题的突破,都将加深你对AI系统运作机制的理解。
在我看来,本地部署AI模型不仅仅是一项技术实践,它更代表了一种对技术自主权的追求,当我们能够在自己掌控的环境中构建和运用智能,创新将不再受制于外部服务的条款与限制,尽管初期可能需要投入时间学习与调试,但由此获得的灵活性、数据安全性与长期成本优势,无疑为个人与组织打开了通往更广阔创新世界的大门,这一切,始于今天你按下运行命令的那一瞬间。

 13888888888
13888888888

 点击咨询
点击咨询 