AI语音克隆模型作为人工智能领域的一项重要技术,近年来逐渐走进大众视野,它不仅为语音合成提供了新的可能性,还在多个行业展现出广泛的应用潜力,对于初次接触这一技术的人来说,了解其基本使用方法十分必要。
要使用AI语音克隆模型,首先需要明确其核心原理,这类模型通常基于深度学习技术,尤其是生成对抗网络(GAN)或变换器架构(Transformer),通过对大量语音数据的学习,提取说话人的声学特征,进而生成高度相似的合成语音,用户无需具备深厚的技术背景,但需遵循一定的操作流程。
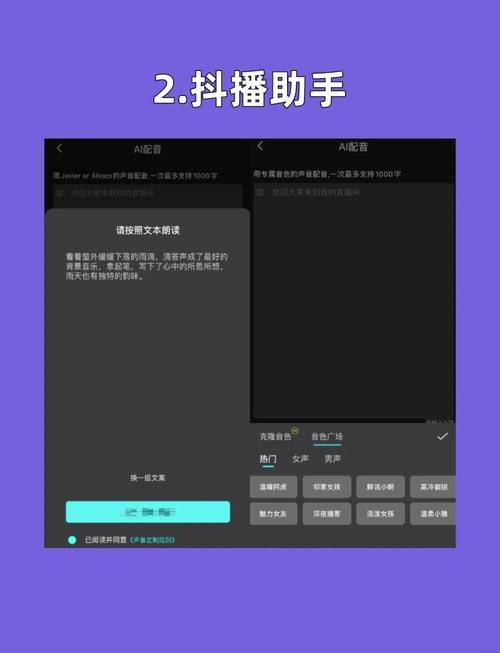
第一步是数据准备,高质量的语音数据是模型效果的基础,系统要求用户提供一段或多段目标说话人的语音样本,样本应尽量清晰、无背景噪音,时长一般在五到二十分钟之间,内容最好涵盖不同的音调、语速和情感表达,以便模型更全面地捕捉声音特征,部分平台支持文本标注,即用户提供语音对应的文字内容,这有助于提高克隆精度。
接下来是模型训练,用户将准备好的语音数据上传至所选平台,启动训练过程,这一阶段耗时较长,取决于数据量和模型复杂度,可能从几十分钟到数小时不等,过程中,系统会自动提取声音特征并构建声学模型,值得注意的是,不同平台的处理方式存在差异:有的提供预训练模型,只需微调即可使用;有的则需从头开始训练,用户可根据实际需求选择适合的方案。
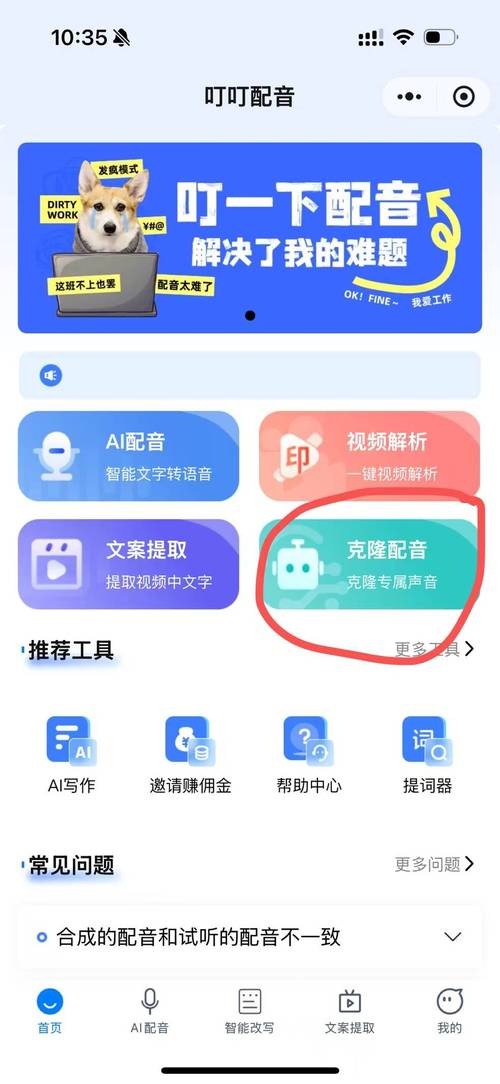
训练完成后,即可进行语音合成,用户输入任意文本,系统会基于已训练的声学模型生成对应的语音文件,输出结果通常支持多种格式,如WAV、MP3等,方便后续使用,部分高级平台还允许用户调节语速、音调和情感参数,以获得更符合预期的效果。
在实际应用中,AI语音克隆技术已渗透至多个领域,在内容创作中,视频制作者可用其为角色配音,节省时间和成本;在教育行业,教师可以生成个性化语音材料,增强学习体验;企业客服系统也能借助这一技术提供更自然的交互服务,该技术在辅助言语障碍人士方面亦有广阔前景。
技术的双刃剑效应不容忽视,语音克隆可能被用于制作虚假音频,带来欺诈或诽谤风险,许多开发方已引入伦理准则和使用限制,例如要求用户获得声音主人的明确授权,或禁止用于违法用途,作为使用者,务必遵守相关法律法规,尊重他人权益。
从个人视角看,AI语音克隆模型的易用性正在不断提升,以往仅有专业机构能掌握的技术,如今已通过云端服务向普通用户开放,部分平台甚至提供图形化界面,使操作更加直观,随着算法优化和硬件升级,语音克隆的效率和自然度有望进一步提升,成为人机交互的重要组成部分,但同时,社会也需建立更完善的法律与道德框架,以引导技术向善发展。

 13888888888
13888888888

 点击咨询
点击咨询 