蓬勃发展的时代,人工智能技术为视频字幕的生成带来了革命性的变化,一个高效准确的AI视频字幕模型,不仅能极大提升内容制作效率,还能改善听障人士的观看体验,并助力视频在全球范围内的传播,制作这样一个模型,是一个融合了多种技术领域的系统性工程。
核心构建流程
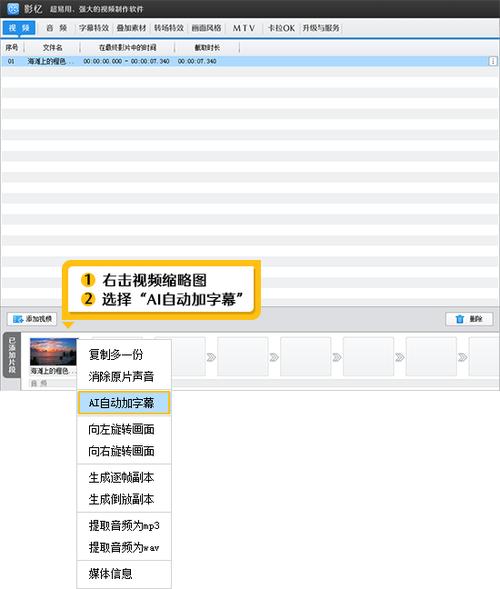
一个完整的AI视频字幕模型的制作,通常遵循以下几个核心步骤:
-
数据收集与预处理: 任何AI模型的基石都是高质量的数据,对于字幕模型,我们需要大量成对的“视频-文本”数据,这些数据可以来自电影、电视剧、纪录片、公开演讲等带有标准字幕的视频源,数据处理环节至关重要,包括视频帧的抽取、音频的分离和降噪、字幕文本的清洗与对齐,文本需要去除特殊符号、统一格式,并确保与音频时间戳精确匹配。

-
语音识别(ASR)模型的构建与训练: 这是模型的核心组件,负责将音频信号转换为文字,现代ASR系统通常基于端到端的深度学习模型,如CTC(Connectionist Temporal Classification)或基于Attention的序列到序列模型,制作过程包括:
- 声学模型训练: 学习音频特征(如梅尔频谱图)与音素或字符之间的映射关系。
- 语言模型训练: 学习语言的语法、句法和常见词序列,用于纠正声学模型可能产生的错误,输出更符合语言习惯的文本。 训练时需要将准备好的音频数据及其对应的文本标注输入模型,通过大量迭代优化模型参数,使其转录准确率不断提升。
-
自然语言处理(NLP)优化: 直接从ASR模型输出的原始文本可能存在断句不合理、缺乏标点、语气词过多等问题,需要引入NLP技术进行后处理优化,这包括:
- 标点符号预测: 通过模型自动为文本添加句号、逗号、问号等标点,使字幕更易读。
- 文本规范化: 将数字、缩写等转换为完整读法(如“2023年”转为“二零二三年”)。
- 语义分段: 根据语义完整性,将长句子分割成适合屏幕显示的字幕段落。
-
集成与部署: 将训练好的ASR模型与NLP模块集成到一个完整的流水线中,这个流水线能够接收视频文件,自动提取音频,进行语音识别,接着进行文本后处理,最后生成带时间戳的SRT或VTT等标准字幕格式文件,之后,需要将模型部署到服务器或云端,提供API接口或用户界面,以便实际应用。
技术考量与挑战
在制作过程中,会面临多项挑战:
- 口音与语种多样性: 模型需要能处理不同的口音、方言乃至多语言场景,这要求训练数据必须足够多样化和有代表性。
- 背景噪声与多人对话: 嘈杂环境下的语音、多人同时讲话(重叠语音)是ASR领域的难题,需要更先进的模型结构和算法来处理。
- 领域适应性: 一个在通用语料上训练的模型,在面对医疗、法律、科技等专业领域术语时,准确率可能会下降,解决方案是采用领域特定的数据进行增量训练或微调。
- 计算资源: 训练先进的深度学习模型需要强大的GPU算力和大量的存储空间,这对个人或小团队来说成本较高。
未来展望与个人思考
AI视频字幕技术正朝着更实时、更精准、更智能的方向演进,随着自监督学习、大模型等技术的发展,未来模型的训练对标注数据的依赖会逐步降低,并能更好地理解上下文语义,甚至能识别出说话人的情绪和语气。
从实践角度来看,对于大多数个人开发者或中小型团队,完全从零开始训练一个工业级的ASR模型并非易事,更现实的路径是基于诸如OpenAI的Whisper等现有的优秀开源模型进行微调(Fine-tuning),根据自己的特定需求(如优化特定口音、识别特定领域的术语)来调整模型,这可以显著降低技术门槛和资源消耗,制作AI视频字幕模型的关键,在于对细节的耐心打磨和对数据质量的严格把控,技术的最终目的是无缝地服务于内容,让技术本身“隐身”于良好的用户体验之后。

 13888888888
13888888888

 点击咨询
点击咨询 