AI人物模型作为人工智能领域的重要分支,正逐渐渗透到数字娱乐、虚拟交互和内容创作等多个领域,其核心目标是通过算法学习并模拟真实或虚构人物的外貌、表情、语言及行为特征,最终生成高度拟人化的数字形象,这样一个模型究竟是如何训练出来的呢?
整个训练过程大致可分为数据准备、模型构建、训练优化和部署应用几个阶段,每个环节都需精心设计与反复调试,缺一不可。

数据是训练AI人物模型的基石,训练所需的数据类型多样,包括图像、视频、语音、文本等,要生成一个虚拟人物的面部表情,就需要大量标注好的面部图像数据,涵盖不同角度、光照和表情变化,数据质量直接影响最终模型的效果,因此必须经过严格的清洗和预处理,常见操作包括去除噪声数据、统一图像尺寸、进行数据增强(如旋转、裁剪、调整亮度)以提升泛化能力。
在数据准备完成后,接下来是模型结构的设计与选择,生成对抗网络(GAN)和变分自编码器(VAE)是两类常用的人物生成模型,GAN包含生成器和判别器两个部分,通过相互博弈提升生成质量;而VAE则擅长学习数据的潜在分布,适合生成连续且多样化的人物特征,Transformer结构也越来越多地应用于语言和动作生成任务中,尤其在构建多模态人物模型时表现突出。
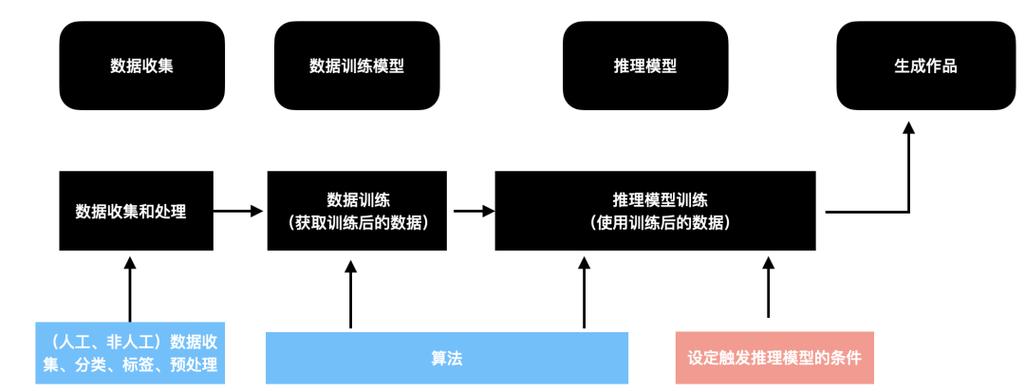
模型确定后,进入实际训练阶段,这一过程通常需要大量的计算资源,如高性能GPU或TPU集群,训练中,通过前向传播计算输出结果,再通过损失函数衡量其与真实数据的差异,最后利用反向传播算法更新模型参数,整个过程往往需要多次迭代,直到模型输出达到预期质量,为避免过拟合,常采用早停策略或正则化方法。
训练过程中还需注意一些常见问题,比如模式崩塌(Mode Collapse)是GAN训练中经常出现的现象,即生成器只能生成少数几种样本,导致输出缺乏多样性,解决这一问题可通过改进网络结构、调整超参数或使用多样性损失函数,训练数据的偏差也需警惕,比如若数据中缺乏某一类人群的信息,模型可能无法准确生成相应形象,这就要求数据收集阶段尽量全面和均衡。

模型训练完成后,还需进行严格的评估与调优,常用的评估指标包括初始分数(IS)、弗雷歇初始距离(FID)等,它们从清晰度、多样性和真实性多个维度衡量生成质量,值得注意的是,自动化指标虽能提供参考,但人物生成模型最终往往需结合人工评价,尤其关注细节的自然度和整体协调性。
训练出一个高质量的AI人物模型不仅依赖技术实现,还要充分考虑伦理与社会影响,生成内容可能涉及肖像权、隐私权甚至虚假信息传播问题,负责任的训练过程应包括数据来源审查、生成内容过滤机制和使用场景约束,以确保技术应用合乎规范。
从技术发展角度看,AI人物模型的训练方法仍在快速演进,更大规模的多模态预训练模型、更高效的分布式训练架构,以及对可控生成能力的增强,都是当前重点研究方向,我们有理由期待出现更智能、更自然、更易用的人物生成模型,进一步推动数字内容产业的创新。
人工智能的本质是延伸人类的创造力和表达能力,而AI人物模型正是这一目标的生动体现,它不仅拓宽了艺术与技术的边界,也为我们理解“人”的本质提供了新的视角,在推进技术的同时,始终保持对伦理的思考和对质量的追求,才能让人工智能真正服务于人。

 13888888888
13888888888

 点击咨询
点击咨询 