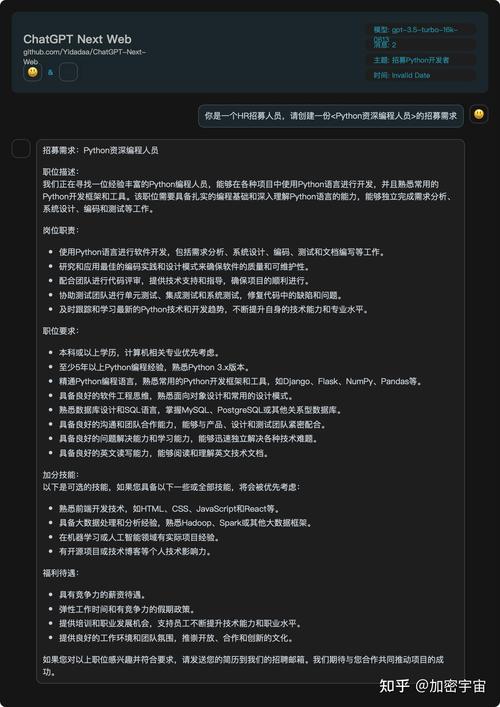
你是否曾好奇,AI模型是如何从无到有被创造出来的?是否觉得这应该是顶级科技公司里博士们的专属领域?随着工具和资源的日益普及,自己动手编写一个基础的AI模型,已经成为许多开发者和爱好者可以实现的挑战,这篇文章将为你勾勒出一条清晰的路径,让你对整个过程有直观的理解。
第一步:打好地基——理解核心概念
在动手之前,我们需要一些基础理论知识,这就像学做菜前,得先认识锅碗瓢盆和基本调料。
- 什么是AI模型? 它是一个数学函数,能够从提供的数据中学习规律,你给它成千上万张猫和狗的图片,它最终能学会区分一张新图片里的动物是猫还是狗。
- 关键术语:
- 机器学习:AI的核心领域,让机器通过数据学习,而非直接编程。
- 神经网络:模仿人脑神经元网络结构的一种流行且强大的机器学习模型,是深度学习的基础。
- 训练:将数据输入模型,不断调整模型内部参数的过程,目的是让模型的预测越来越准。
- 损失函数:衡量模型预测结果与真实答案差距的尺子,训练的目标就是最小化这个“损失”。
- 优化器:一种算法,负责在训练过程中如何调整参数以减小损失。
你不需要成为所有这些概念的专家才能开始,但一个大致的印象能帮助你在后续步骤中明白自己在做什么。
第二步:选择你的工具——编程语言与框架
工欲善其事,必先利其器,选择合适的工具能事半功倍。
- 编程语言:Python 是绝对的主流,它语法简洁,拥有极其丰富的AI库和活跃的社区,是入门和实践的首选。
- 开发框架:这是真正的“利器”,它们提供了构建和训练模型所需的预制组件和高效计算能力。
- PyTorch:以灵活性和动态性见长,深受研究人员和希望深入理解细节的开发者的喜爱,它的代码非常直观,易于调试。
- TensorFlow / Keras:TensorFlow是一个功能强大的工业级框架,而Keras是其官方的高层API,它像搭积木一样简化了模型构建过程,对初学者非常友好。
建议:如果你是新手,可以从 PyTorch 或 Keras 开始,它们能让你更专注于模型逻辑而非复杂的实现细节。
第三步:从“Hello World”开始——你的第一个模型
不要一开始就挑战图像识别或自动驾驶,从一个最简单的任务入手,比如手写数字识别,这个经典项目相当于AI界的“Hello World”。
大致流程如下:
- 准备数据:使用现成的数据集,如MNIST(包含大量手写数字图片和对应标签),框架通常都内置了这类常用数据集。
- 构建模型:使用你选择的框架,像搭乐高一样,组合不同的“层”来构建一个简单的神经网络,一个输入层(接收图片像素)、几个隐藏层(学习特征)、一个输出层(输出0-9每个数字的概率)。
- 训练模型:
- 将数据输入模型,得到预测结果。
- 用损失函数计算预测与真实标签的差距。
- 通过优化器,根据差距反向调整模型每一层的参数。
- 重复这个过程成千上万次,模型的准确率会逐渐提升。
- 评估模型:使用模型从未见过的测试集数据来检验它的真实表现,你会得到一个准确率,比如98%,这意味着100个手写数字里,它能认对98个。
完成这一步,你将获得巨大的成就感,并真正理解训练的核心循环。
第四步:迭代与深化——从简单到复杂
成功运行第一个模型后,你可以沿着几个方向深入:
- 尝试不同的模型结构:从简单的全连接网络,到更强大的卷积神经网络,感受不同架构的优势。
- 探索新的任务:从图像分类扩展到自然语言处理(如情感分析、文本生成)、语音识别等。
- 使用预训练模型:这是一种高效的方法,你可以下载在超大规模数据集上训练好的成熟模型,然后用自己的数据对它进行“微调”,使其适应你的特定任务,这大大节省了时间和计算资源。
- 关注数据处理:你会发现,数据的质量在很大程度上决定了模型的上限,学习数据清洗、增强和管理的技巧至关重要。
可能遇到的挑战与心态准备
自己写AI模型的过程绝非一帆风顺,你会遇到:
- 硬件限制:复杂的模型训练需要强大的算力,尤其是GPU,初期你可以利用Google Colab、Kaggle等平台提供的免费GPU资源。
- 调试困难:模型不work的原因千奇百怪,可能是数据问题、模型结构问题或代码bug,这需要耐心和系统性排查。
- 数学知识:要想走得更远,线性代数、概率论和微积分的基础知识会非常有帮助,它们能让你更深刻地理解模型的工作原理。
这个过程更像是一场马拉松而非短跑,重要的不是一口气跑完全程,而是享受学习、探索和解决问题的乐趣,每一次模型的成功收敛,每一个精度的提升,都会带来独特的兴奋感,AI模型的创造之旅,是一扇通向理解智能本质的大门,而推开这扇门的钥匙,现在就握在你的手中。

 13888888888
13888888888

 点击咨询
点击咨询 