在当今技术飞速发展的时代,人工智能已经从一个遥远的概念,演变为赋能各行各业的核心驱动力,利用AI进行模型设计,正成为提升效率、激发创新的关键路径,无论您是产品经理、工程师,还是充满好奇的探索者,理解并掌握这一过程,都将为您打开一扇通往未来的大门。
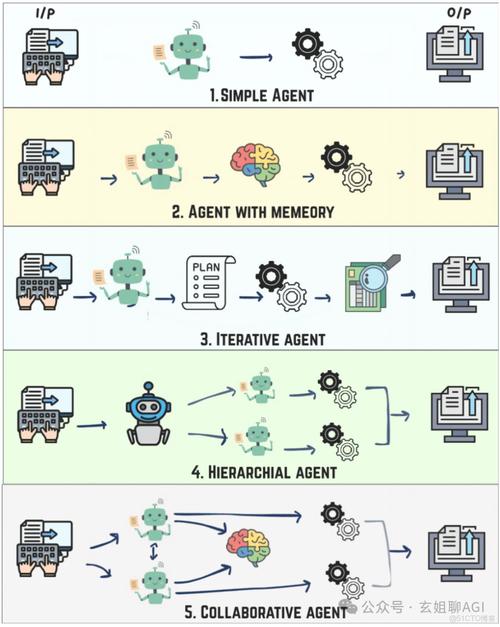
如何着手利用AI来设计一个有效的模型呢?这个过程并非一蹴而就,而是一个系统化、循环迭代的工程,我们可以将其梳理为几个核心阶段。

第一阶段:明确定义目标是成功的基石
任何模型的设计都始于一个清晰、具体的目标,这个目标必须可以被量化地衡量,与其说“我想提升网站用户体验”,不如将其定义为“通过AI模型,预测用户可能点击的内容,将首页点击率提升5%”,一个模糊的目标会让后续的所有工作失去方向,在此阶段,您需要回答几个关键问题:这个模型要解决什么具体问题?成功的标准是什么?它将为业务或用户带来何种价值?
第二阶段:数据是模型的“燃料”与“基石”
AI模型的性能上限,很大程度上由数据质量决定,没有高质量的数据,再精巧的算法也是无源之水。
- 数据收集: 根据您的目标,确定需要哪些数据,这些数据可能来自用户行为日志、数据库、公开数据集,甚至是网络爬虫,关键在于,数据必须与您要解决的问题高度相关。
- 数据清洗与标注: 原始数据往往充满“噪音”,此步骤需要处理缺失值、异常值以及不一致的格式,对于监督学习,您还需要对数据进行标注,为图片打上“猫”或“狗”的标签,为邮件标记“垃圾”或“非垃圾”,这是一项繁重但至关重要的工作,数据的准确性直接决定了模型判断的可靠性。
- 数据探索与分析: 通过可视化和统计分析工具,深入了解数据的分布、特征之间的关系,这一步能帮助您发现潜在规律,并为后续的特征工程提供灵感。
第三阶段:特征工程与模型选择
如果说数据是原材料,那么特征就是经过加工、能让模型更好理解的“营养品”。
- 特征工程: 这是将原始数据转换为更能代表预测问题特征的过程,将“出生日期”转换为“年龄”,从“地址”中提取“城市”,或者将文本数据转换为数值向量,优秀的特征工程能显著提升模型性能,有时其贡献甚至超过模型算法本身。
- 模型选择: 面对众多的AI算法,如何选择?这取决于您的任务类型(是分类、回归还是聚类?)、数据量大小、特征维度以及对模型可解释性的要求,对于初学者,可以从逻辑回归、决策树等经典模型开始;处理图像问题,卷积神经网络(CNN)是首选;处理序列数据(如文本、语音),循环神经网络(RNN)或Transformer架构更为合适,不必一味追求最复杂的模型,简单且高效的模型往往是工程上的首选。
第四阶段:模型训练与评估——在实践中检验
这是将数据、特征和算法融合,赋予模型“智能”的核心环节。
- 划分数据集: 通常将数据分为三部分:训练集(用于模型学习)、验证集(用于调整超参数和模型选择)和测试集(用于最终评估模型性能),务必确保测试集的独立性,以得到无偏的性能评估。
- 训练与调优: 模型在训练集上学习数据中的模式,您需要通过验证集来调整模型的“超参数”(如学习率、网络层数等),这是一个反复试验的过程,旨在找到让模型表现最佳的组合。
- 性能评估: 使用测试集,通过精确率、召回率、F1分数、均方误差等指标,客观地衡量模型的泛化能力(即处理新数据的能力),避免模型在训练集上表现优异,却在测试集上表现不佳的“过拟合”现象。
第五阶段:部署上线与持续迭代
一个在测试集上表现完美的模型,若不能投入实际应用,便失去了价值。
- 模型部署: 将训练好的模型封装成API接口、集成到应用程序或嵌入到边缘设备中,使其能够接收真实世界的数据并返回预测结果。
- 监控与维护: 模型上线并非终点,现实世界的数据分布会随时间变化(概念漂移),导致模型性能衰减,必须建立持续的监控机制,跟踪模型的表现,并定期用新数据重新训练模型,使其保持最佳状态。
在整个过程中,工具的选择可以大大降低门槛,对于编程基础薄弱的使用者,可以尝试Google的AutoML、百度的EasyDL等自动化机器学习平台,它们简化了特征工程和模型调优的复杂性,对于希望深入掌控的开发者,TensorFlow、PyTorch等框架提供了极大的灵活性。
我们必须认识到,AI模型设计是一个充满创造性与严谨性的探索之旅,它要求我们既有宏观的业务视野,又能沉下心来处理细致的数据问题,每一次迭代,都是对问题理解的深化,最重要的是,要始终保持一颗好奇心,勇于尝试,不怕失败,在实践中不断积累经验,当您亲手打造的第一个模型成功解决了一个实际问题时,您会深刻体会到,AI并非神秘的黑盒,而是我们手中强大的、可以塑造未来的工具。

 13888888888
13888888888

 点击咨询
点击咨询 