想找到合适的AI翻唱模型,却感觉像是大海捞针?面对五花八门的模型名称和平台,确实容易让人眼花缭乱,别担心,这篇指南将为你梳理清晰的思路,带你一步步找到最适合你声音和需求的那个“它”。
理解核心:AI翻唱模型是什么?
AI翻唱模型是一个经过大量音频数据训练的智能程序,它学会了如何将一个人的声音特征(音色、演唱风格)从原始录音中分离出来,并精准地转换到另一首歌曲的旋律和伴奏上,从而实现“用你的声音唱别人的歌”。
这个过程主要依赖于一种叫做“声码器”的技术,它负责分析和重建声音,一个优秀的模型,能够在转换后最大程度地保留你声音的独特质感,同时完美贴合新歌曲的节奏与情感。

主流的模型类型与选择
AI翻唱领域主要有以下几类模型,它们各有侧重:
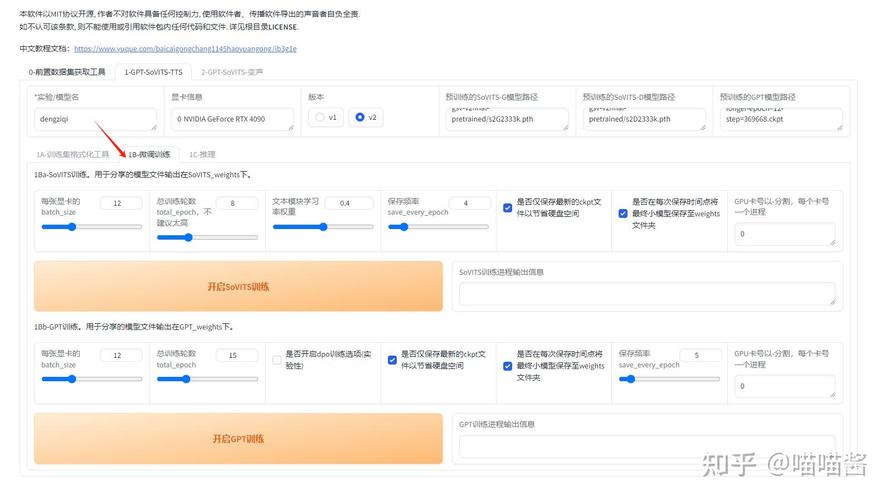
开源模型:技术爱好者的乐园 这类模型通常在GitHub等开发者社区发布,如著名的so-vits-svc系列,它们的最大优势是免费、灵活度高,允许使用者进行深度定制和训练。
- 适合人群:具备一定计算机基础,愿意花时间钻研技术,追求极致个性化效果的玩家。
- 寻找途径:直接在GitHub上搜索相关关键词,关注项目的“Star”数量和更新频率,这通常是项目活跃度和质量的参考。
集成式应用:新手友好的快速通道 许多AI翻唱软件或在线平台已经将复杂的模型封装成简单易用的界面,你无需理解底层代码,只需上传干声文件(清唱音频),选择目标歌曲,软件会自动调用内置模型完成转换。
- 适合人群:绝大多数普通用户和入门级创作者,希望快速上手,立即体验AI翻唱乐趣。
- 寻找途径:在各大应用商店、软件下载站或通过行业媒体推荐,搜索“AI翻唱”、“声音克隆”等关键词,关注用户评价和教程丰富度。
垂直平台模型:专精于音乐创作的引擎 一些专注于AI音乐生成的平台,会投入大量资源研发自家模型,这些模型往往针对音乐场景做了深度优化,在音质、自然度上可能有独特优势,并且集成了丰富的伴奏库和后期处理工具。
- 适合人群:对音质有较高要求,希望在一个平台内完成创作、分享全流程的音乐爱好者。
- 寻找途径:留意音乐人社区、音频论坛的讨论,往往能发现这些专业平台的身影。
如何判断一个模型的优劣?
找到模型只是第一步,如何甄别其好坏至关重要,你可以从以下几个维度进行考量:
- 音质保真度:转换后的声音是否清晰、干净,有无明显的电子杂音或失真,优秀模型能保留声音的细节和呼吸感。
- 转换自然度:生成的演唱是否流畅,与伴奏的融合度如何,有没有出现音调突兀、节奏错位的情况。
- 情感保持能力:能否保留原声音中的情感色彩,还是变得机械平淡,这是区分普通模型与优秀模型的关键。
- 对原声要求:一个好的模型应具备一定的包容性,不要求极其专业的录音环境,试试看用手机录制的人声效果如何。
- 社区活跃度:无论是开源模型还是商业平台,一个活跃的用户社区意味着你能快速获得帮助、找到教程并共享资源。
为你量身定做的寻找策略
你的需求和背景,是选择模型的根本出发点。
- 如果你是纯新手,只想尝鲜:从集成式应用或在线平台开始是最佳选择,它们操作简单,能让你在几分钟内看到成果,建立兴趣和信心。
- 如果你有一定技术背景,乐于折腾:可以探索开源模型世界,这里充满了可能性,你可以训练出独一无二的、专属于你的声音模型。
- 如果你是音乐创作者,追求专业效果:应重点关注垂直音乐平台的模型,并对比不同平台在音质、版权和工具链上的优势。
开始你的第一次实践
选定模型后,准备工作同样重要:
- 准备优质干声:这是成功的一半,找一个安静的环境,用耳机收听伴奏,录制一段清晰、无背景噪音的清唱音频,格式推荐WAV或FLAC等无损格式。
- 选择合适的目标歌曲:初期建议选择伴奏清晰、旋律不太复杂的歌曲进行尝试,成功率更高。
- 耐心调试参数:很多模型提供了音高、响度、融合度等参数,不要害怕尝试微调,这往往是让效果更完美的关键一步。
AI翻唱技术正以前所未有的速度进化,新的模型和工具层出不穷,保持好奇,持续学习,勇于实践,是玩转这个领域的不二法门,这个过程本身就是一种充满乐趣和惊喜的创造,最重要的是,找到那个能让你的声音自由歌唱的工具,享受科技带来的全新艺术表达方式。

 13888888888
13888888888

 点击咨询
点击咨询 