人工智能聊天模型正逐渐融入日常生活的各个角落,从客户服务到个人助手,其应用日益广泛,如果您对构建属于自己的AI聊天模型充满兴趣,那么了解其核心步骤与关键考量至关重要。
理解AI聊天模型的核心
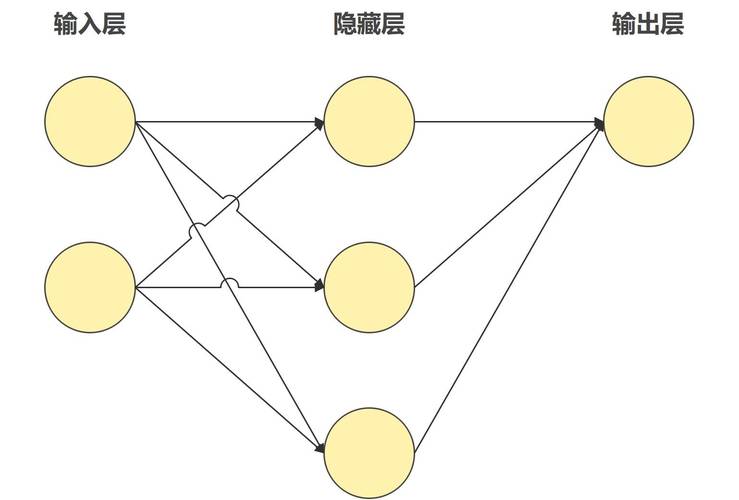
AI聊天模型,本质上是一个经过大量数据训练,能够理解和生成人类语言的计算程序,它并非真正“理解”语义,而是通过分析海量文本中的统计规律,学习到单词、短语和句子之间的关联性,从而预测在特定语境下最合适的回应,当前,基于Transformer架构的大语言模型是这一领域的主流技术方向。
构建模型的步骤与方法
构建一个功能完善的AI聊天模型,通常需要经历以下几个关键阶段:
-
明确目标与定义范围 在开始任何技术工作之前,必须首先明确模型的用途,它是用于回答特定领域问题的专业助手,还是用于日常闲聊的通用伴侣?目标决定了后续所有环节的方向,一个范围清晰、功能专注的模型,往往比一个大而全的模型更容易成功,也更能为用户提供有价值的体验。
-
数据收集与精心处理 数据是模型的基石,其质量直接决定模型性能的上限。
- 收集:根据既定目标,从公开数据集、经过授权的专业文本或合规的网络资源中收集高质量的文本数据,数据的规模、多样性和相关性缺一不可。
- 清洗与预处理:原始数据通常包含大量噪声,需要进行清洗,包括去除无关字符、纠正拼写错误、标准化格式等,随后,进行分词(将句子分解为单词或子词单元)、去除停用词等预处理操作,为模型训练做好准备。
-
模型选择与训练策略 对于大多数开发者而言,从头开始训练一个大型模型需要巨大的计算资源和数据量,既不经济也不现实,更实用的策略是:
- 选择预训练模型:基于开源社区提供的、已经过海量数据预训练的模型(例如一些优秀的开源模型)作为起点,这些模型已经具备了强大的语言理解能力。
- 微调:使用您自己准备好的、与特定任务相关的专业数据集,对预训练模型进行有针对性的再训练,这个过程能够让模型适应您的特定领域和对话风格,学会执行您期望的任务,选择合适的微调算法(如指令微调、人类反馈强化学习等)对最终效果影响显著。
-
评估与持续迭代 模型训练完成后,需要通过一套客观的指标和主观的人工评测来评估其性能,评估内容应包括回答的准确性、相关性、流畅性、安全性以及是否可能存在偏见,根据评估结果,对模型进行多轮的优化和迭代,这是一个持续改进的过程。
-
部署与集成应用 将训练好的模型部署到服务器或云平台上,并提供应用程序编程接口,以便将其集成到网站、应用程序或聊天界面中,部署时需充分考虑系统的稳定性、响应速度和安全防护。
构建过程中的关键考量
在构建过程中,有几个方面需要特别关注:
- 计算资源:模型的训练,尤其是微调大型模型,对GPU算力有较高要求,需要提前规划好计算资源。
- 道德与责任:必须高度重视模型可能产生的偏见、歧视性言论或虚假信息,通过精心设计的数据筛选、设置内容安全过滤器以及持续的监控,来尽力规避这些风险,确保技术应用合乎规范。
- 用户体验:一个成功的聊天机器人不仅在于技术的先进,更在于交互的自然与友好,设计清晰的对话流程、赋予模型适当的个性,都能极大提升用户体验。
- 持续学习:上线并非终点,通过收集用户的反馈数据,模型可以进行持续的优化和学习,以适应不断变化的用户需求和语言习惯。
构建AI聊天模型是一个融合了数据科学、软件工程和语言学的综合工程,它既充满挑战,也极具吸引力,从明确一个小而实际的目标开始,逐步积累经验和数据,是走向成功的稳妥路径,随着技术的不断进步和工具的日益成熟,参与创造智能对话体验的门槛正在逐步降低,每一个精心构建的模型,都是向着更自然、更有价值的人机交互迈出的一步。

 13888888888
13888888888

 点击咨询
点击咨询 