在当今全球化的数字时代,AI翻译模型成为许多企业和个人实现跨语言交流的重要工具,无论是用于网站内容本地化、商务沟通还是日常翻译,正确设置这些模型能够显著提升翻译准确性和效率,作为一名长期关注人工智能发展的从业者,我将在本文中分享如何设置AI翻译模型的关键步骤和实用建议,帮助您优化使用体验。
了解AI翻译模型的基本原理
AI翻译模型通常基于深度学习技术,尤其是神经机器翻译(NMT)架构,这类模型通过大量双语数据训练,学习语言之间的映射关系,从而实现自动翻译,常见的模型类型包括基于Transformer的架构,如Google的BERT或OpenAI的GPT系列衍生版本,理解这些基本原理有助于在设置过程中做出明智决策,避免盲目调整参数。
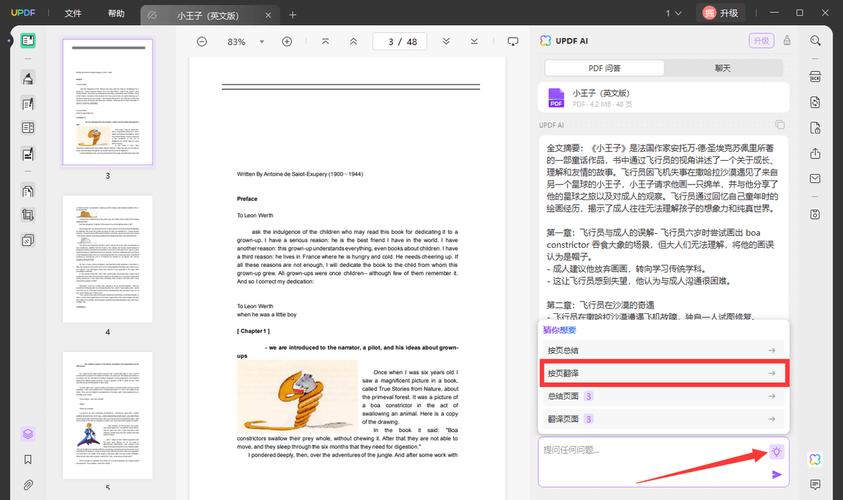
选择适合的模型类型
设置AI翻译模型的第一步是选择合适的模型类型,根据您的需求,可以考虑预训练模型或自定义模型,预训练模型如谷歌翻译API或微软Translator,适合快速部署,无需大量数据训练,如果您的应用场景涉及专业术语或特定领域(如医疗、法律),则可能需要自定义模型,通过微调预训练模型来适应独特需求,在选择时,评估模型的性能指标,如BLEU分数或人工评估结果,确保其与您的语言对和目标受众匹配。
配置关键参数
模型参数设置直接影响翻译质量和效率,以下是一些核心参数及其调整方法:

- 学习率:控制模型在训练过程中更新权重的速度,过高可能导致不稳定,过低则延长训练时间,从默认值如0.001开始,根据损失曲线逐步调整。
- 批量大小:决定每次训练迭代中处理的样本数量,较大的批量大小可加速训练,但需要更多内存;较小批量则适合精细调优,建议根据硬件资源选择,例如从32或64开始测试。
- 层数和隐藏单元数:这些参数影响模型的复杂度和表达能力,对于一般应用,使用标准设置即可;若处理复杂语言结构,可适当增加层数,但需注意过拟合风险。
- 优化器选择:Adam或SGD是常用优化器,Adam适合大多数场景,SGD则在稳定训练中表现更佳,实验不同优化器,结合早停法来防止过拟合。
参数调整是一个迭代过程,使用验证集监控性能,并根据结果微调,如果翻译结果出现大量错误,可能是学习率过高或数据质量不足所致。
数据预处理和训练
高质量的数据是AI翻译模型成功的基础,在设置过程中,数据预处理至关重要:
- 数据收集:获取大量高质量的双语语料,例如从公开数据集或专业渠道,确保数据覆盖目标语言的各种用法,包括口语和书面语。
- 清洗和标准化:去除重复、错误或无关的内容,统一文本格式(如大小写、标点),对于中文等语言,还需进行分词处理,以提高模型理解能力。
- 数据增强:通过回译或同义词替换等方法扩充数据集,增强模型泛化性。
训练阶段需注意以下要点:
- 划分数据集为训练集、验证集和测试集,比例通常为70:15:15。
- 使用GPU加速训练,并设置检查点保存最佳模型。
- 监控损失函数和准确率,如果验证集性能下降,可能需调整参数或增加数据。
训练完成后,进行多轮测试,确保模型在真实场景中稳定运行。
部署和集成
将训练好的模型部署到生产环境是设置的最终步骤,根据您的技术栈,可以选择云服务或本地部署:
- 云服务:如AWS、Google Cloud或Azure,提供托管式翻译API,简化维护和扩展,只需配置API密钥和端点,即可集成到网站或应用中。
- 本地部署:适合对数据隐私要求高的场景,使用Docker容器化模型,并结合REST API实现调用,确保服务器资源充足,以处理高并发请求。
在集成过程中,设置缓存机制和限流策略,以提升响应速度和稳定性,添加日志监控和错误处理,便于实时调试。
优化和维护
AI翻译模型的设置并非一劳永逸,持续优化能保持其竞争力:
- 定期更新:随着语言演变和新数据出现,重新训练模型或应用增量学习。
- 用户反馈循环:收集用户对翻译结果的评价,用于改进模型,建立反馈系统,标记错误翻译并纳入训练数据。
- 性能评估:使用自动化工具和人工审核结合,检查翻译的流畅度和准确性,关注常见问题,如文化敏感词或歧义处理。
考虑能耗和成本因素,选择高效的模型架构,如量化或剪枝技术,以减少资源消耗。
个人观点
在我看来,AI翻译模型的设置是一门结合技术与艺术的实践,它要求用户不仅掌握参数调优,还需理解语言本身的多样性,随着自适应学习和多模态模型的发展,设置过程将更加智能化,但核心仍在于以用户为中心,平衡效率与质量,通过逐步积累经验,任何从业者都能打造出高效的翻译解决方案,助力全球沟通无障碍。

 13888888888
13888888888

 点击咨询
点击咨询 