在人工智能项目的实际开发中,模型训练固然消耗大量计算资源和时间,但训练完成后如何妥善保存模型,是确保项目价值得以延续的关键一步,一个未被正确保存的模型,就如同辛苦酿造的美酒没有封存好瓶盖,其价值会迅速流失。
模型保存的核心价值
保存模型不仅仅是为了“存档”,它主要服务于三个核心目的:

- 推理与部署:训练好的模型需要被加载到生产环境中,用于处理真实世界的数据,进行预测或生成内容。
- 继续训练:在遇到训练中断、需要追加新数据或进行微调时,可以从之前保存的检查点继续训练,避免从头开始。
- 分享与复用:将模型分享给团队成员或开源社区,促进协作和知识复用,避免重复造轮子。
主流框架的保存方法
不同的深度学习框架提供了各自的模型保存机制,但其核心思想是相通的:将模型的结构和学到的参数(权重与偏置)持久化到存储设备上。
PyTorch框架
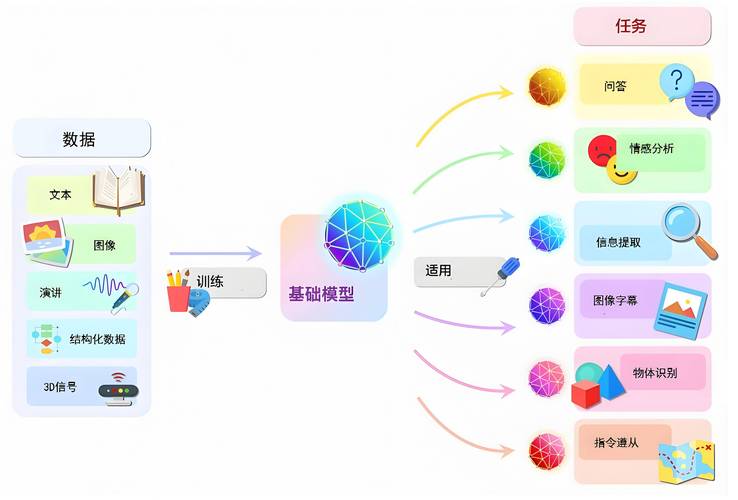
PyTorch提供了灵活且强大的保存方式,主要分为两种:
保存整个模型(推荐用于推理) 这种方法使用
torch.save()直接保存整个模型对象,它的优点是简单直观,加载时无需重新定义模型结构。
import torch import torchvision.models as models # 假设我们有一个训练好的模型 model = models.resnet18(pretrained=True) # ... 训练过程 ... # 保存整个模型 torch.save(model, 'model_complete.pth') # 加载时,直接读取即可 model_loaded = torch.load('model_complete.pth') model_loaded.eval()这种方式有时可能因为模型类的定义路径问题而导致加载失败。
仅保存模型状态字典(推荐用于继续训练和部署) 这是更健壮和常用的方法,它只保存模型的可学习参数(即
state_dict),而不保存模型结构本身。# 保存状态字典 torch.save(model.state_dict(), 'model_state_dict.pth') # 加载时,需要先实例化模型结构,再加载参数 model_new = models.resnet18() # 这里不需要pretrained=True model_new.load_state_dict(torch.load('model_state_dict.pth')) model_new.eval()这种方式要求加载代码中必须有与保存时完全一致的模型类定义,因此通常会将模型定义代码与训练脚本分离,确保其可复用性。
TensorFlow/Keras框架
Keras API极大地简化了模型的保存过程。
SavedModel格式(标准部署格式) 这是TensorFlow官方推荐的格式,适用于跨平台部署。
# 保存为SavedModel格式 model.save('my_saved_model') # 加载模型 loaded_model = tf.keras.models.load_model('my_saved_model')H5格式 这是一种单一文件格式,便于管理和分享。
# 保存为.h5文件 model.save('my_model.h5') # 加载模型 loaded_model = tf.keras.models.load_model('my_model.h5')仅保存权重 与PyTorch的状态字典类似,可以只保存权重。
# 保存权重 model.save_weights('my_weights.h5') # 加载权重(需先构建结构相同的模型) new_model = create_model() # 假设这是一个创建模型结构的函数 new_model.load_weights('my_weights.h5')
关键考量与最佳实践
选择正确的保存格式只是第一步,一个专业的AI工程师还会关注以下方面:
保存检查点:在长时间训练中,定期保存检查点至关重要,这可以通过PyTorch的
torch.save结合epoch编号,或使用Keras的ModelCheckpoint回调函数来实现,这样,即使训练过程因意外中断,也能从最近的一个检查点恢复,最大限度地减少损失。格式的选择:如果模型需要部署到TensorFlow Serving、TensorFlow.js或TensorFlow Lite等环境,必须使用
SavedModel格式,如果只是在自己的Python环境中复用,state_dict或H5格式都是不错的选择。包含元数据:一个良好的习惯是,将模型的元数据与模型文件一同保存,这可以是一个简单的JSON文件,记录模型的版本、训练数据描述、输入输出格式、训练超参数、性能指标等,这对于模型的版本管理和后续维护极具价值。
安全性与完整性:确保模型文件存储在安全、可靠的位置,并进行定期备份,对于重要模型,可以考虑计算文件的哈希值(如MD5或SHA-256)以验证其完整性,防止文件损坏或被篡改。
模型保存是一项将动态的计算过程转化为静态、可复用资产的关键技术,它要求开发者不仅理解框架的API调用,更要具备工程化的思维,考虑到部署、维护和协作的全链路需求,一个被妥善保存的模型,才是真正具备生命力的AI成果。

 13888888888
13888888888

 点击咨询
点击咨询 