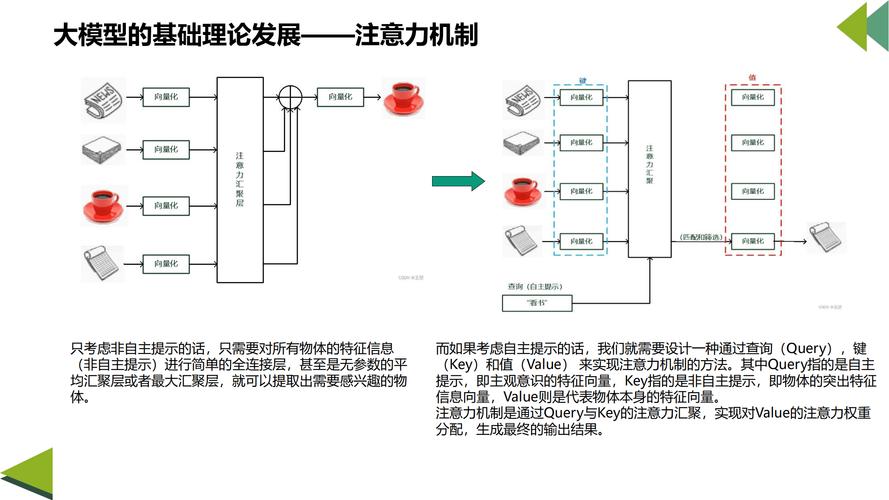
理解AI模型的基本原理
AI模型的核心是通过算法处理数据,从中提取规律并完成特定任务,无论是图像识别、自然语言处理还是预测分析,模型的能力来源于训练阶段对大量数据的学习,在医疗领域,模型通过分析数万份病例数据,能够辅助医生识别早期疾病特征;在金融行业,AI可基于历史交易数据预测市场趋势,理解这一原理,是实际应用的前提。
实际应用场景的分类
自动化流程优化
AI模型可替代重复性高、规则明确的任务,制造业中的质检环节,通过视觉识别模型自动检测产品缺陷,效率比人工提升数倍,客服领域,智能对话系统处理80%的常见问题,仅将复杂情况转交人工,这类应用的核心价值在于降低成本与提升效率。决策支持系统
在需要复杂分析的场景中,AI模型可作为决策者的“智囊”,零售企业利用用户行为数据预测爆款商品,指导库存管理;城市规划部门通过交通流量模型优化信号灯配时,此类应用依赖高质量数据与模型的解释性,需确保结果可被人类理解与验证。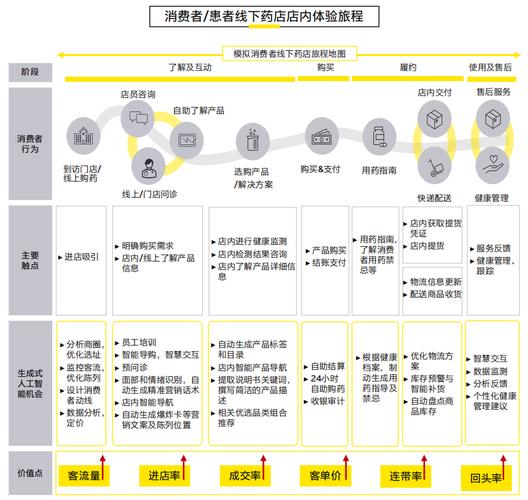
个性化服务升级
AI模型能够根据个体特征提供定制化服务,教育平台通过分析学生的学习轨迹,推送个性化习题;健康管理类App结合用户体征数据,生成专属饮食建议,此类应用需平衡精准度与隐私保护,避免过度依赖算法导致用户信任度下降。
落地的关键步骤

明确需求与可行性评估
并非所有场景都适合引入AI模型,企业需先梳理业务痛点,是否因人力成本过高导致利润压缩”或“是否存在数据未被充分利用的决策盲区”,同时评估数据储备、技术基础与预算,避免盲目投入。数据准备与模型选择
数据的质量直接影响模型效果,需进行数据清洗(如去除重复、异常值)、标注(如图像分类标签),并划分训练集与测试集,模型选择需权衡性能与成本:预训练大模型适合复杂任务,但算力消耗高;轻量化模型更适合嵌入式设备或实时响应场景。持续迭代与效果监控
模型上线后需建立反馈机制,电商推荐系统需跟踪点击率与转化率,定期用新数据微调模型参数;工业设备故障预测模型需根据实际误报率优化阈值,需关注数据分布的动态变化,防止“模型漂移”导致性能下降。
常见挑战与应对策略
数据孤岛问题
跨部门或跨机构的数据难以互通时,可采用联邦学习技术,在不共享原始数据的前提下联合训练模型,多家医院合作构建疾病预测模型,各自数据保留在本地,仅交换加密后的参数更新。算力资源限制
中小企业可采用混合云方案:训练阶段使用公有云的高性能算力,推理阶段部署在本地边缘设备,选择量化压缩技术(如将32位浮点数转为8位整数),降低模型运行成本。安全与伦理风险
建立数据匿名化机制,避免用户隐私泄露,对于医疗、金融等高风险领域,需设计模型可解释性模块,例如输出特征重要性权重,帮助人类审核决策依据。
未来发展的核心趋势
AI模型正从“通用型”向“垂直领域深度定制”演变,法律行业需要理解专业术语的NLP模型,农业领域需适配不同气候条件的病虫害识别系统,小型化与实时化成为关键需求,如手机端可直接运行的轻量级模型,或工业传感器上的实时异常检测算法。
个人观点
AI模型的价值不在于技术本身,而在于其解决实际问题的能力,企业应避免跟风堆砌技术概念,而是从具体业务场景出发,优先选择能快速验证效果的试点项目,建立跨领域协作团队——数据科学家、业务专家与合规人员共同参与,才能让AI从实验室走向真实世界,真正创造可持续的商业与社会效益。

 13888888888
13888888888

 点击咨询
点击咨询 