明确目标与场景
训练模型的第一步是明确需求。
AI模型的应用场景千差万别:图像识别需要卷积神经网络(CNN),自然语言处理依赖Transformer架构,而时间序列预测可能更适合循环神经网络(RNN)。
关键问题:
- 模型需要解决的具体问题是什么?
- 预期输出形式是分类、回归还是生成?
- 对模型的精度和速度有何要求?
若目标是开发一个识别植物病害的模型,需优先考虑轻量化设计,以便部署到移动设备;若用于金融预测,则需强化模型的时序分析能力。
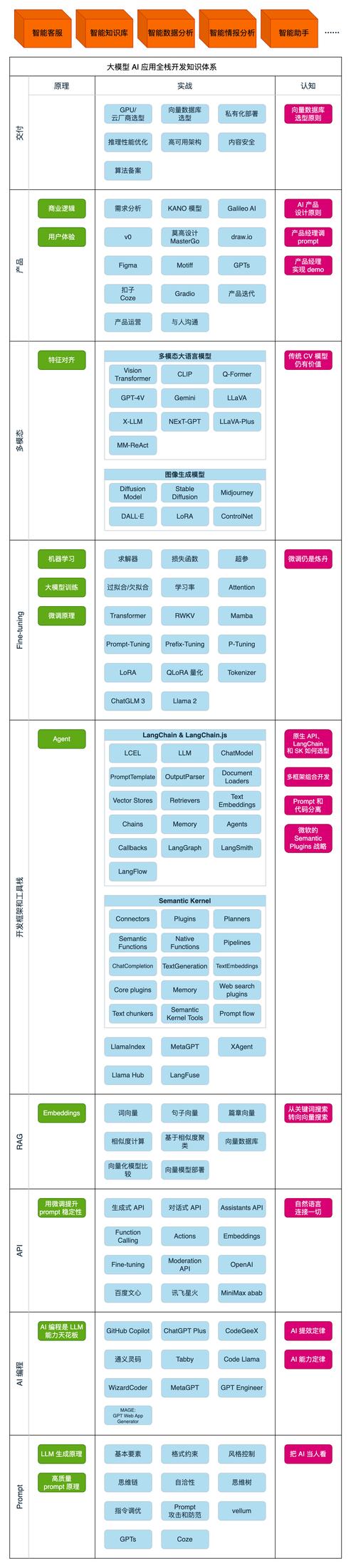
数据准备:质量决定上限
数据是模型训练的基石,一个常见误区是过度追求数据量而忽视质量。
数据处理的四大环节:
- 收集
- 公开数据集(如Kaggle、Google Dataset Search)
- 爬虫工具合法抓取(注意遵守Robots协议)
- 自有数据整理(日志、用户行为记录等)
- 清洗
- 删除重复、残缺样本
- 处理异常值(如医疗数据中的负数年龄)
- 统一格式(图像尺寸、文本编码)
- 标注
- 监督学习必须依赖精准标注
- 半监督学习可结合少量标注数据与大量未标注数据
- 增强(Augmentation)
- 图像:旋转、裁剪、调整对比度
- 文本:同义词替换、句式改写
- 音频:添加噪声、变速处理
某电商平台曾通过数据增强技术,将商品识别模型的准确率提升了12%。
模型选择与框架搭建
根据任务类型选择合适的基础架构后,还需考虑开发效率与部署成本。
主流框架对比:
| 框架 | 优势 | 典型场景 |
|---------|------------------------|----------------|
| TensorFlow | 生态完善,适合生产环境 | 工业级部署 |
| PyTorch | 动态计算图,调试灵活 | 学术研究 |
| Keras | 接口简洁,快速原型开发 | 入门教学 |
创新方向:

- 使用预训练模型(如BERT、ResNet)进行迁移学习
- 结合多个模型的集成学习策略
- 针对边缘设备的模型压缩技术
某创业团队利用Hugging Face的预训练模型,仅用两周时间就完成了客服问答系统的初期搭建。
训练过程与调优技巧
启动训练后,需持续监控模型表现并动态调整策略。
核心参数解析:
- 学习率(Learning Rate):过高导致震荡,过低收敛缓慢(建议0.001-0.0001)
- 批量大小(Batch Size):显存允许下适当增大可提升稳定性
- 训练轮次(Epoch):配合早停法(Early Stopping)防止过拟合
调优三板斧:
- 对抗过拟合
- 增加Dropout层(丢弃率0.2-0.5)
- 采用L1/L2正则化
- 交叉验证(推荐5折以上)
- 提升泛化能力
- 混合不同分布的数据
- 引入对抗样本训练
- 使用标签平滑技术
- 加速收敛
- 自适应优化器(AdamW优于传统SGD)
- 学习率预热(Warmup)
- 余弦退火调度器
某自然语言处理项目通过分层学习率设置(底层参数小幅度更新,顶层大幅度调整),使模型训练效率提高了40%。
模型评估与部署
训练完成后需通过多维度验证:
- 定量指标:准确率、F1值、AUC-ROC曲线
- 定性分析:可视化注意力机制、错误案例归因
- 压力测试:高并发请求下的响应延迟
部署时建议:
- 使用ONNX格式实现跨平台兼容
- 通过Docker容器化封装依赖环境
- 设计API接口时加入限流与熔断机制
持续迭代的闭环
AI模型不是一次性的产品,定期收集新数据、监控线上表现、进行A/B测试,才能保持竞争力,某推荐系统每月更新一次用户行为数据,并通过在线学习(Online Learning)实现动态优化。

 13888888888
13888888888

 点击咨询
点击咨询 