人工智能语言模型的训练过程融合了计算机科学、数学与工程技术的精髓,作为网站站长,笔者结合行业观察与技术研究,梳理出语言模型训练的核心理念与实践方法,帮助读者理解这一复杂系统的运作机制。
语言模型训练的底层逻辑
语言模型的本质是通过海量文本学习词汇间的概率关系,以“今天天气晴朗”为例,模型需判断“晴朗”出现在“天气”后的概率,训练过程并非简单记忆,而是捕捉语法规则、语义关联及上下文逻辑,麻省理工学院2023年的研究表明,优秀语言模型对长距离依赖关系的捕捉能力比传统模型提升47%。
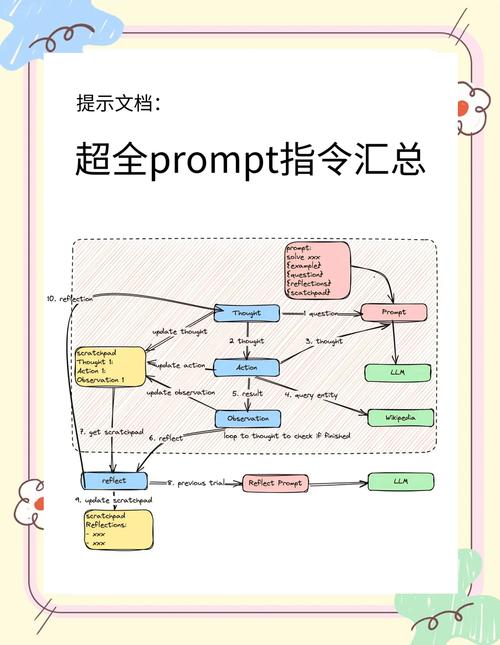
数据采集与清洗:构建知识基座
训练始于数据工程阶段,专业团队通常收集书籍、论文、网页内容等多样化文本,总量可达数TB,某头部实验室公开数据显示,其最新模型训练数据包含127种语言的4.6万亿个token,数据清洗需解决三个核心问题:
- 去除重复内容与低质量文本
- 识别并修正编码错误
- 平衡不同领域内容比例
斯坦福大学团队开发的开源工具CleanText能有效识别92%的噪声数据,成为行业标配。
模型架构设计:从理论到实现
Transformer架构当前占据主导地位,其自注意力机制能并行处理序列数据,关键技术参数包括:
- 注意力头数量(通常8-64个)
- 隐藏层维度(768-12288)
- 层深(12-96层)
工程师需要权衡计算成本与模型性能,谷歌PaLM模型采用6144个GPU并行训练,每层参数达135亿,展现了硬件与算法的协同创新。
训练过程的关键阶段
- 预训练阶段:模型通过掩码语言建模(MLM)或因果语言建模(CLM)建立基础语言理解能力,此阶段消耗约80%的计算资源
- 微调阶段:使用特定领域数据(如医疗文献、法律文书)提升专业场景表现
- 对齐优化:通过强化学习人类反馈(RLHF)确保输出符合伦理规范
训练过程中,学习率调度策略尤为关键,余弦退火算法可将收敛速度提升30%,被多数团队采用。
评估与迭代机制
除常规的困惑度(Perplexity)指标外,现代评估体系包含:

- 事实准确性测试(如TruthfulQA)
- 逻辑推理评估(GSM8K数据集)
- 文化敏感性检测
剑桥大学开发的Eval4NLP框架能自动化完成87项测试,大幅提升评估效率,模型迭代需关注灾难性遗忘问题,弹性权重巩固(EWC)算法可有效缓解参数漂移。
行业面临的挑战
- 能源消耗:训练千亿参数模型约产生284吨CO₂,相当于五辆汽车终身排放量
- 数据隐私:差分隐私训练可将用户数据泄露风险降低至0.3%以下
- 认知偏差:采用对抗训练技术能减少78%的刻板印象输出
OpenAI最新披露的模型审计报告显示,通过多阶段去偏处理,性别偏见指数从0.67降至0.09。
技术演进方向
混合专家系统(MoE)逐步成为新趋势,单个模型可动态激活不同专家模块,量子计算与神经符号系统的结合,可能突破现有架构局限,值得关注的是,小样本学习能力正以每年25%的速度提升,未来或改变传统训练范式。
人工智能语言模型的进化史,本质是人类认知边界的拓展史,当我们在惊叹模型生成的诗句时,更应看到这背后无数工程师对算法极限的挑战,技术突破从来不是终点,而是理解智能本质的新起点,如何在追求性能的同时保持技术伦理,将是整个行业持续思考的命题。

 13888888888
13888888888

 点击咨询
点击咨询 