理解AI模型的基本原理
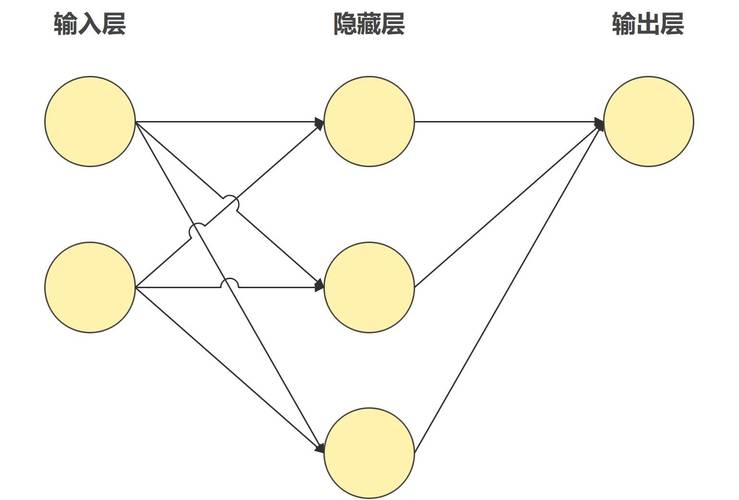
人工智能模型的核心是通过算法从数据中提取规律,并基于这些规律进行预测或决策,搭建AI模型的第一步是理解其工作原理,模型通常由输入层、隐藏层和输出层构成,通过调整各层之间的参数(权重和偏置),使模型能够从训练数据中逐步优化性能,在图像识别任务中,模型需要学会从像素中识别边缘、形状等特征,最终完成分类。
明确目标与场景需求
在动手搭建模型前,需明确以下问题:

- 任务类型:分类、回归、聚类还是生成任务?
- 数据特征:数据类型(文本、图像、音频)、数据规模及质量如何?
- 性能指标:准确率、召回率、F1分数或自定义指标?
- 资源限制:硬件条件(GPU/CPU)、时间成本、部署环境。
若目标是搭建一个电商评论情感分析模型,需收集足够的中文评论数据,定义正向、中性、负向标签,并选择适合自然语言处理的架构。
数据准备:模型成功的关键
高质量的数据决定了模型的上限,数据准备需遵循以下步骤:
- 数据收集:通过公开数据集(如Kaggle)、爬虫或企业自有数据库获取原始数据。
- 数据清洗:剔除重复值、处理缺失值、纠正错误标签,文本数据需去除特殊符号或停用词。
- 数据标注:监督学习任务需人工标注或半自动标注工具辅助。
- 数据增强:对图像数据进行旋转、裁剪,或对文本进行同义词替换,提升泛化能力。
- 划分数据集:按7:2:1或类似比例分为训练集、验证集和测试集,避免过拟合。
选择合适的模型架构
根据任务需求选择基础模型框架:
- 传统机器学习模型:适用于小规模结构化数据,如逻辑回归、随机森林。
- 深度学习模型:
- 卷积神经网络(CNN):图像识别、视频分析。
- 循环神经网络(RNN):时序数据(如股票预测)、自然语言处理。
- Transformer:长文本理解、机器翻译(如BERT、GPT系列)。
- 预训练模型:利用Hugging Face、TensorFlow Hub等平台的预训练权重,快速迁移到特定任务。
模型训练与调优技巧
- 参数初始化:使用Xavier或He初始化方法,避免梯度消失或爆炸。
- 损失函数选择:分类任务常用交叉熵损失,回归任务用均方误差。
- 优化器设置:Adam、SGD等优化器需调整学习率(建议从0.001开始尝试)。
- 正则化方法:L1/L2正则化、Dropout层防止过拟合。
- 超参数调优:使用网格搜索、随机搜索或贝叶斯优化工具(如Optuna)寻找最佳参数组合。
训练过程中,需监控验证集损失和指标变化,若验证集表现持续低于训练集,可能需增加数据量或简化模型结构。
模型评估与部署
- 性能评估:
- 分类任务:混淆矩阵、ROC曲线、AUC值。
- 目标检测:mAP(平均精度均值)。
- 生成任务:BLEU、ROUGE分数。
- 错误分析:针对预测错误的样本,分析是数据偏差、特征缺失还是模型容量不足导致。
- 部署方式:
- 本地部署:将模型导出为ONNX或TensorRT格式,嵌入应用程序。
- 云端API:通过Flask或FastAPI封装模型,提供HTTP接口调用。
- 边缘设备:使用TensorFlow Lite或Core ML优化模型,适配移动端或物联网设备。
持续迭代与维护
AI模型上线后需持续监控其表现:
- 数据漂移检测:定期检查输入数据分布是否偏离训练集。
- 模型再训练:根据新数据增量训练或全量更新模型版本。
- 用户反馈闭环:收集用户对预测结果的反馈,优化模型或标注流程。
关于技术工具的建议
- 框架选择:初学者可从PyTorch入手,其动态计算图更易调试;工业级项目推荐TensorFlow。
- 可视化工具:TensorBoard、Weights & Biases监控训练过程。
- 自动化管道:使用Kubeflow或Airflow构建从数据预处理到模型部署的完整流水线。
个人观点
搭建AI模型并非一劳永逸的过程,而是一个需要不断迭代的工程,许多初学者容易陷入“追求最新技术”的误区,但实际上,合理利用现有工具、扎实处理数据、深入理解业务场景,往往比盲目尝试复杂模型更有效,在资源有限的情况下,一个精心调优的随机森林模型可能比未经优化的深度网络更具实用价值,技术终归服务于需求,清晰的目标和稳健的执行才是成功的关键。

 13888888888
13888888888

 点击咨询
点击咨询 