认识AI大模型的核心逻辑
AI大模型的核心在于“学习”与“生成”,通过海量数据训练,模型能够识别模式、理解语言逻辑,并根据输入内容生成符合人类认知的输出,以ChatGPT为例,其训练数据覆盖书籍、论文、网页文本等,使其具备了对话、写作、编程辅助等能力,这种技术的突破并非偶然,而是深度学习算法、算力提升和数据规模共同作用的结果。
理解AI大模型的运作逻辑,需关注三个关键点:
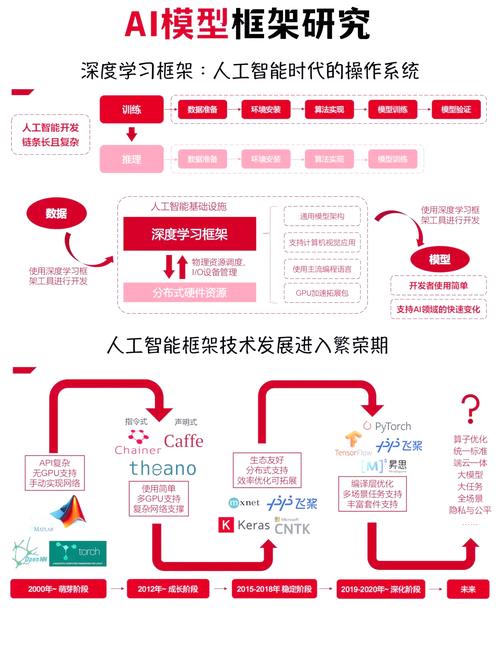
- 预训练与微调:模型先通过通用数据学习基础能力(如语言理解),再通过特定领域数据优化针对性任务。
- 参数规模:千亿级参数赋予模型更强的记忆和推理能力,但同时也带来更高的算力需求。
- 交互设计:用户输入的指令质量直接影响输出效果,清晰的提示词(Prompt)能显著提升结果精准度。
普通人如何上手体验?
即使没有技术背景,普通人也能通过以下方式快速体验AI大模型的魅力:
选择合适平台
国内外主流平台如ChatGPT、文心一言、Claude等均提供免费或付费接口,ChatGPT允许用户通过简单注册直接对话;文心一言则针对中文场景优化,更适合本土用户测试。
掌握基础指令技巧
- 明确需求:避免模糊提问,将“写首诗”改为“写一首七言绝句,主题是江南春雨,包含比喻手法”,输出质量会显著提升。
- 分步引导:复杂任务可拆解为多轮对话,例如先让模型列出文章大纲,再逐步完善各部分内容。
- 角色设定:通过赋予模型特定身份(如“资深编辑”“数学教师”)调整输出风格。
探索实用场景
- 创意生成:撰写短视频脚本、设计营销口号、辅助小说创作
- 知识整理:快速提取长文要点、生成会议纪要、整理学习笔记
- 技能辅助: debug代码错误、翻译润色外语文档、制定健身计划
某教育机构从业者曾分享案例:使用AI大模型在20分钟内完成原本需要3小时的课程设计框架,效率提升近10倍。

技术爱好者如何深入探索?
对开发者或科技从业者而言,AI大模型提供了更广阔的实验空间:
本地化部署
通过Hugging Face等开源社区获取模型权重(如LLaMA、BLOOM),结合自有数据进行微调,需注意算力门槛:训练175B参数模型需要数千张A100显卡,但消费级显卡已能支持70亿参数模型的本地推理。
工具链实践
- LangChain:构建基于大模型的自动化工作流,如连接数据库实现智能问答
- AutoGPT:尝试让AI自主拆解复杂任务并分步执行
- LoRA技术:通过低秩适配器在有限算力下高效微调模型
技术前沿追踪
2023年Meta提出的“模型即服务”(MaaS)架构、Google的稀疏化训练技术、OpenAI的多模态迭代方向,都值得持续关注,斯坦福大学基础模型研究中心(CRFM)定期发布的评估报告,为技术选型提供重要参考。
行业应用的创新突破
AI大模型正在重塑多个领域的运作模式:
- 医疗诊断:梅奥诊所试点使用大模型分析患者病史,辅助医生快速定位罕见病症
- 金融风控:摩根士丹利部署内部模型,实时扫描百万级交易数据识别欺诈模式
- 智能制造:特斯拉工厂将大模型与物联网结合,实现设备故障的预测性维护 生产**:新华社“AI主播”已能自动生成新闻视频,时效性提升至分钟级
某电商平台数据显示,接入大模型的智能客服系统使客诉处理效率提升40%,同时降低30%人力成本。
争议与思考:技术双刃剑
AI大模型的普及也引发多重争议:
- 信息真实性:模型可能生成看似合理实则错误的内容,需建立结果验证机制
- 职业替代焦虑:创意类工作是否会被AI取代的讨论持续升温
- 能耗问题:单次大模型训练的碳排放相当于5辆汽车整个生命周期的排放量
欧盟已出台《人工智能法案》,要求生成式AI必须标注内容来源;中国科学院等机构正研发“绿色大模型”,通过算法优化降低能耗。
个人观点
作为持续关注AI发展的从业者,我认为当前仍处于技术爆发初期,与其担忧“取代”,不如聚焦“增强”——就像摄影术没有消灭绘画,而是催生了新艺术形式,掌握“人机协作”能力将成为核心竞争力:知道何时依赖模型增效,何时需要人类判断,这种动态平衡才是智能化时代的生存法则,未来的创新,或许正藏在“人类想象力”与“机器计算力”的交叉地带。

 13888888888
13888888888

 点击咨询
点击咨询 