在人工智能领域,构建一个大型模型是一项复杂而系统的工程,它融合了前沿的算法理论、庞大的数据工程和巨大的计算资源,这个过程并非一蹴而就,而是需要严谨的规划与执行。
核心基石:数据、算力与算法
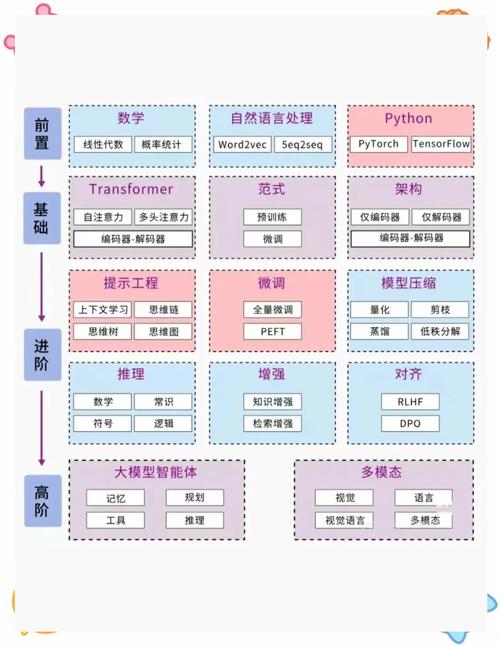
构建大模型的根基,立于三大支柱:高质量的数据、强大的计算能力和先进的算法架构。
数据是模型的血液,一个模型的能力上限,很大程度上由其训练数据的质量和规模决定,这里所说的数据,并非简单的数量堆砌,它需要经过精心的采集、清洗和标注,确保其具备多样性、准确性和代表性,训练一个能理解多国语言和文化的模型,就需要覆盖全球不同地区、不同语境的海量语料,数据预处理环节,如去除噪声、纠正错误、统一格式,是保障模型学习效果的关键步骤。
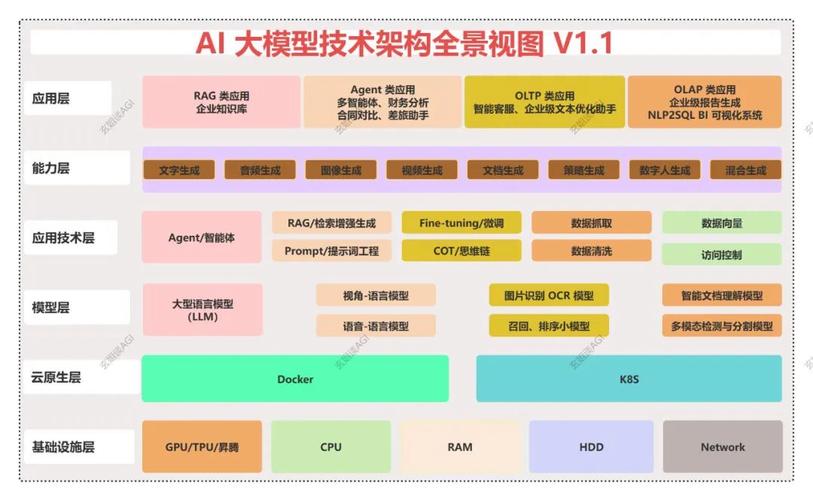
算力是模型的引擎,大模型的训练需要处理数以万亿计的参数,这离不开高性能计算集群的支持,通常由成千上万的GPU或专用AI芯片协同工作,这些硬件设备需要稳定的电力供应和高效的冷却系统,算力成本构成了模型研发的主要开支,对计算资源的有效管理和优化,直接关系到项目的可行性与效率。
算法是模型的蓝图,Transformer架构的出现,是自然语言处理领域的里程碑,它通过自注意力机制有效捕捉长距离依赖关系,成为当今绝大多数大模型的核心,研究者们会在这一基础架构上进行持续的创新与微调,例如改进优化器、设计更高效的注意力机制,或者探索新的模型缩放定律,以期用更少的资源获得更优的性能。

构建流程:从蓝图到精雕
一个典型的大模型构建过程,可以概括为几个关键阶段。
明确目标与架构设计 在开始任何工作之前,必须清晰地定义模型的目标,是要做一个通用的对话助手,还是一个专注于代码生成的工具?目标决定了技术选型,随后,基于目标设计模型架构,确定参数规模、层数、注意力头数等关键超参数,这一步如同建筑的设计图纸,奠定了后续所有工作的基础。
大规模数据筹备与处理 根据模型目标,从公开数据集、经过授权的互联网信息以及其他合规渠道收集原始数据,接下来是繁重且至关重要的数据清洗工作,包括去重、过滤低质量内容、敏感信息脱敏等,之后,将非结构化数据(如文本、图像)转化为模型可以理解的数值形式,即 Tokenization(分词/标记化),这个过程需要精心设计的词表,以平衡模型的表达能力和计算效率。
分布式模型训练 这是最消耗计算资源的阶段,将处理好的数据输入到初始化后的模型中,通过复杂的数学运算,让模型学习数据中的模式与规律,训练通常采用分布式并行策略,将数据和模型本身拆分到多个计算节点上同步进行,在这个过程中,监控训练损失(Loss)和各项评估指标的变化至关重要,它帮助工程师判断模型是否在朝着正确的方向学习,并及时调整训练策略。
指令微调与人类反馈对齐 预训练得到的模型虽然拥有丰富的知识,但可能无法很好地遵循人类的指令或符合特定的价值观,需要第二个训练阶段——指令微调,使用高质量的指令-回答对数据,教导模型如何与人交互,更进一步,会采用基于人类反馈的强化学习技术,让模型生成的回答更加符合人类的偏好,更加安全、有用和无害,这是让模型从“博学”变得“智慧”和“可控”的关键一步。
全面评估与部署上线 模型训练完成后,需要通过一套全面的评估体系来衡量其性能,这包括在标准学术数据集上的基准测试,以及针对具体应用场景的专项评估,必须进行严格的安全性、偏见和伦理审查,通过评估后,模型会被封装成服务,通过API或应用的形式部署到生产环境,接受真实世界的检验。
面临的挑战与未来方向
构建大模型的道路充满挑战,巨大的资源消耗带来了高门槛和高碳排放问题,模型有时会产生看似合理实则错误的“幻觉”信息,训练数据中存在的偏见也可能被模型放大,导致输出结果不公,版权、隐私和模型滥用等伦理法律问题也亟待解决。
展望未来,我们可能会看到几个发展趋势:模型架构将持续进化,追求更高的计算效率和性能;高质量、合规数据的价值将愈发凸显;降低训练和推理成本的技术将成为研究热点;多模态融合(结合文本、图像、音频等)的能力将变得更加普遍;围绕大模型的治理和监管框架也会逐步完善。
个人观点
构建AI大模型,已经从纯粹的研究探索,演变为一项牵涉多学科的系统工程,它考验的不仅仅是一个团队的技术深度,更是其工程实现能力、资源整合能力以及对技术社会影响的深思熟虑,成功的模型背后,是无数次迭代、调试和对细节的执着追求,对于有志于此的团队而言,扎实的基础、清晰的路径规划以及对负责任AI的坚定承诺,是穿越这片充满机遇与挑战领域的重要指引。

 13888888888
13888888888

 点击咨询
点击咨询 