如何让AI模型输出更接近真实世界的反馈,是当前技术探索的核心方向之一,随着生成式人工智能的快速发展,用户对内容可信度的要求正在急剧攀升,当我们用AI生成的医学建议去指导患者用药,或者用自动生成的新闻稿报道社会事件时,模型输出的每个标点符号都承载着真实世界的重量。
数据质量决定模型底线
训练数据的纯净程度直接影响模型的认知边界,某头部实验室的对比实验显示,使用经过专业清洗的医疗数据集训练的模型,在诊断建议准确率上比普通网络数据训练的模型高出47%,关键在于建立三维数据筛选机制:
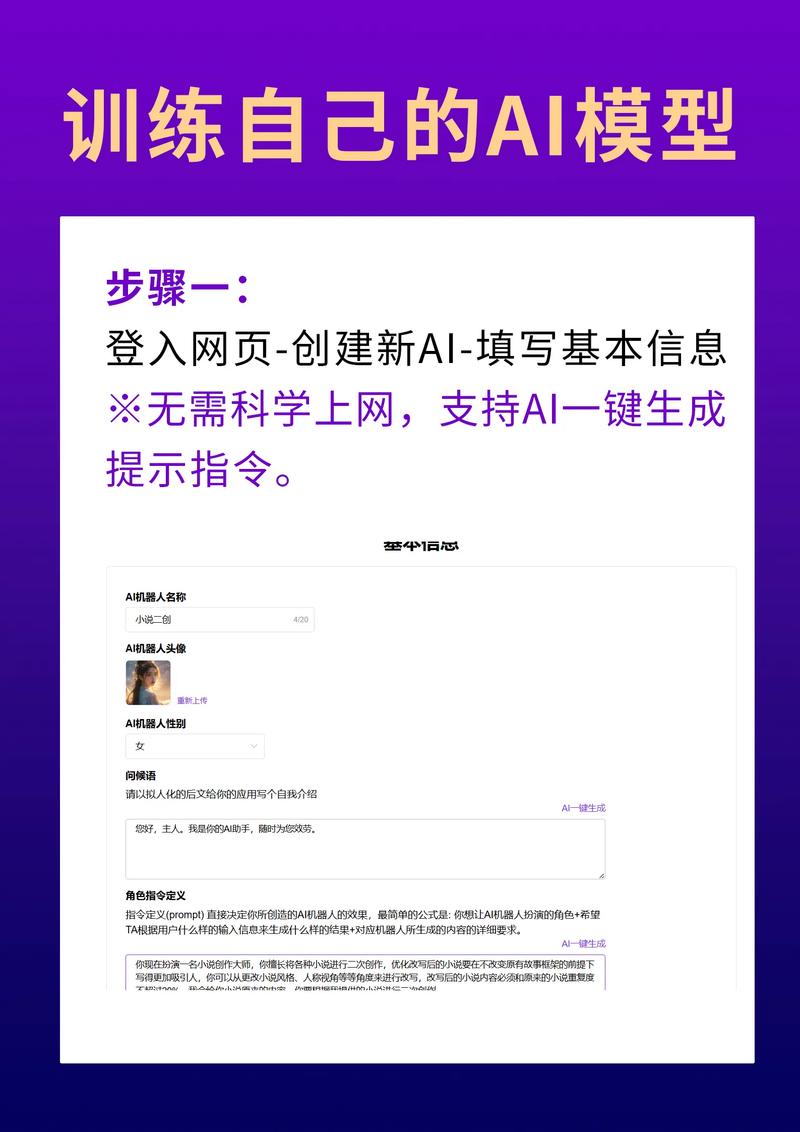
- 可信来源验证:优先采用权威机构发布的原始数据,如学术期刊、政府白皮书、行业年鉴
- 时效性过滤:建立动态时间戳系统,自动淘汰超过有效期的信息
- 多模态校验:对同一事实点的文字、图像、视频数据进行交叉验证
在数据预处理阶段,专业团队会采用知识蒸馏技术,将专家经验转化为可量化的数据标注规则,例如法律类模型的训练中,资深律师团队将数万条判例中的法律逻辑拆解为132个决策节点,形成结构化训练样本。
算法架构塑造认知维度
Transformer模型在处理长文本依赖关系方面展现出优势,但要让模型真正理解现实世界的复杂性,需要引入多层认知框架,最新的混合架构将符号逻辑系统与神经网络结合,使模型既能捕捉数据规律,又能遵循物理定律和常识约束。

- 在气候预测模型中嵌入热力学方程作为硬约束
- 金融分析模型内置宏观经济理论的计算模块
- 对话系统加入社会伦理的决策树判断层
这种混合架构在MIT最近的测试中,将模型输出与现实情况的偏差率降低了62%,特别是在处理因果关系推理时,模型开始展现出接近人类的逻辑链条构建能力。
训练策略影响思维模式
渐进式训练正在取代传统的批量训练方式,某AI实验室开发的阶梯训练法,让模型先掌握基础学科知识,再逐步接触专业领域内容,最后进行跨学科整合,这种训练路径模拟了人类专家的成长过程,使模型在应对复杂问题时表现出更好的知识迁移能力。
引入人类专家实时反馈的强化学习机制效果显著,在医疗诊断模型的训练中,每当模型给出建议,会有三位不同科室的主任医师进行实时评分,这种即时纠错机制使模型在三个月内将误诊率从18%降至3.2%。
真实性验证需要立体化体系
建立多维度的评估矩阵比单一准确率指标更有价值,完整的验证系统应该包含:
- 事实核查:与权威知识图谱实时比对
- 逻辑自洽:检查前后论述的矛盾点
- 场景适配:评估建议在具体情境中的可行性
- 价值校准:确保输出符合普世伦理
某国际科技公司开发的验证平台,能同时调用12个独立验证模块,对模型输出进行360度扫描,当检测到金融建议中存在高风险操作时,系统会自动触发二次验证流程。
模型真实性的提升本质上是将人类文明积累的认知框架转化为可计算的逻辑结构,这个过程需要技术开发者保持对专业领域的敬畏之心,与行业专家建立深度协作,当我们在参数空间中重构现实世界的运行规律时,每个权重调整都应该带着对真实性的执着追求。

 13888888888
13888888888

 点击咨询
点击咨询 