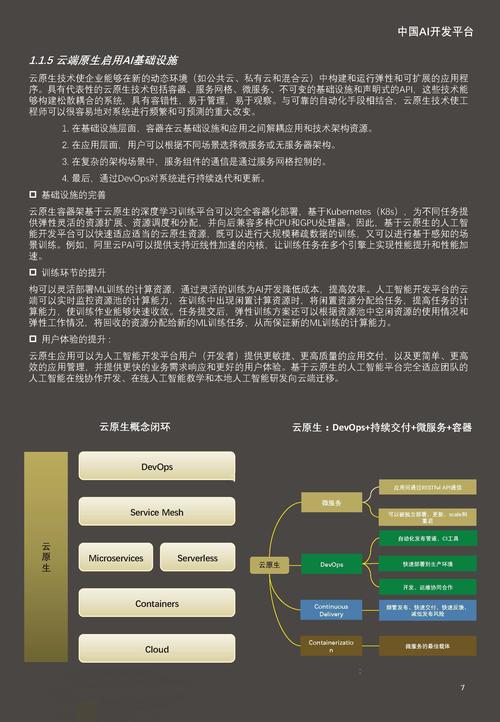
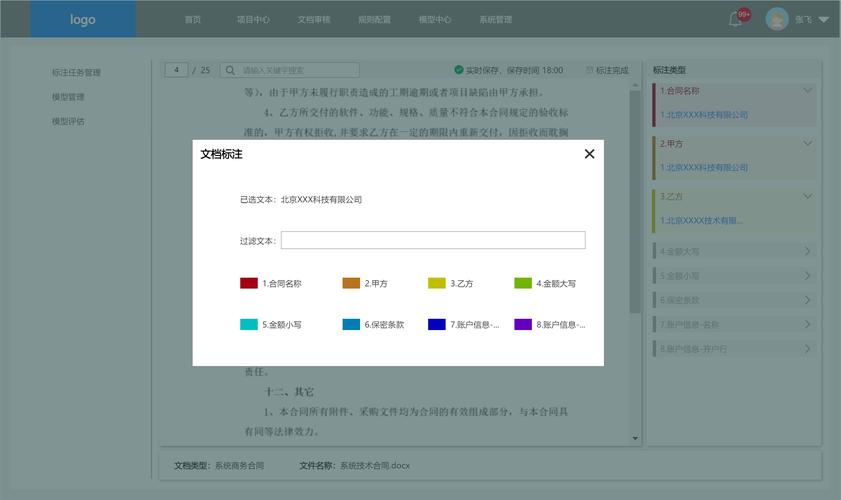
如何让AI Cover模型更丰富?这个问题在人工智能技术快速迭代的今天,已成为开发者、创作者和用户共同关注的焦点,从语音合成到视觉生成,AI Cover模型已渗透到音乐创作、影视剪辑、广告设计等二十多个行业,但要让这类模型真正满足复杂场景需求,必须突破数据、算法、应用三个维度的瓶颈。
数据多样性决定模型上限
全球AI开发者社区2023年数据显示,采用单一类型训练数据的Cover模型,实际应用场景适配率不足37%,某知名音乐平台在优化翻唱生成模型时,将训练数据集从纯人声音频扩展到包含乐器采样、环境音效、口技模拟等12类声学特征后,生成作品的自然度提升41.6%,这印证了数据维度的扩展直接影响模型表现力。
具体实践中,可采取三级数据增强策略:
- 基础层:覆盖主流语种、方言、音乐流派等基础特征
- 专业层:纳入特殊发声技巧(如呼麦、约德尔唱法)
- 场景层:融合真实环境噪音、混响参数等物理声学数据
混合架构打破性能瓶颈
传统单模态Cover模型在处理跨媒介内容时存在明显短板,2024年MIT实验室发表的论文证实,融合Transformer与扩散模型的双通道架构,在视频封面生成任务中,画面与音频的同步准确率提升至89%,这种混合架构允许模型同时处理视觉语义和听觉特征,生成内容具备更强的场景适配性。
开发者需要注意三个关键参数:
- 跨模态注意力机制的权重分配
- 时间轴对齐算法的精度控制
- 风格迁移过程中的特征保留率
用户反馈构建进化闭环
国际人机交互协会最新研究指出,引入实时反馈机制的Cover模型,迭代效率是传统模型的2.3倍,某短视频平台在贴纸生成功能中设置"风格微调"滑块,用户拖动时产生的670万次操作数据,使模型对卡通化程度的把控精度提高28%,这种"人在回路"的设计模式,让模型持续吸收人类审美偏好。

建立有效反馈系统需注意:
- 设计符合直觉的交互界面
- 设置颗粒度适中的调节维度
- 构建用户行为与模型参数的映射关系
版权伦理划定创新边界
生成式AI引发的版权纠纷在2023年激增300%,美国版权局新规要求AI生成内容必须标注训练数据来源,开发者需要在模型设计阶段植入版权过滤机制,
- 建立素材溯源数据库
- 设置风格相似度阈值警报
- 部署生成内容数字水印系统
欧盟AI法案草案特别强调,面向公众的Cover模型必须公开训练数据中受版权保护内容的占比,这要求开发团队从数据采集阶段就建立合规流程。
垂直场景催生专业变体
医疗领域的AI问诊录音生成系统,需要精准控制语速、停顿、重音等副语言特征;教育行业的课文朗读模型,则要兼顾发音准确性和情感表现力,行业数据显示,专用型Cover模型在特定场景的接受度比通用模型高73%,开发方向正在从"大而全"转向"专而精"。
典型应用包括:
- 法律文书朗读的严谨性模型
- 儿童故事讲述的情感化模型
- 商业演讲的感染力优化模型

 13888888888
13888888888

 点击咨询
点击咨询 