在生成式人工智能技术快速发展的当下,将定制化AI模型融入Stable Diffusion(以下简称SD)已成为创作者提升生产力的关键技能,本文将以图文结合的方式,系统讲解模型部署的全流程操作,并针对实际应用中可能遇到的疑难问题提供解决方案。
模型部署前的必要准备
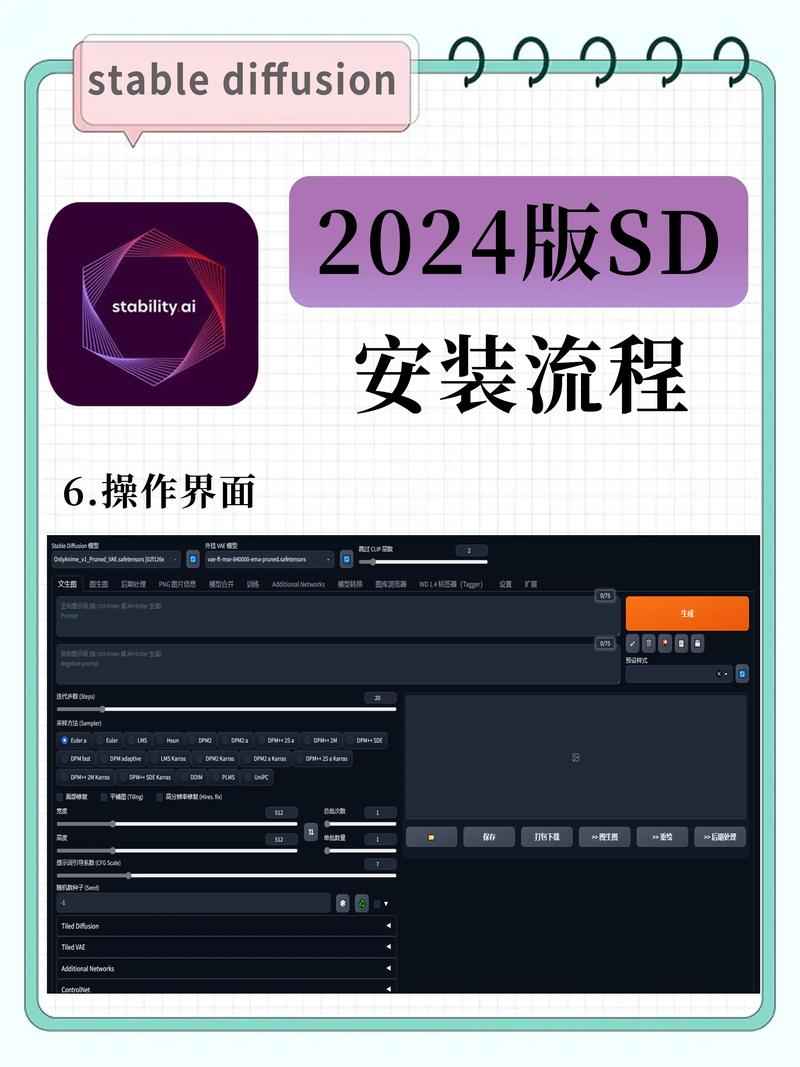
模型文件识别
SD支持的主要模型格式包括.ckpt(检查点文件)和.safetensors(安全张量格式),建议通过文件大小初步判断模型类型——基础模型通常超过2GB,而LoRA等微调模型多在100-500MB之间。环境配置核查
• 确认已安装Python 3.8及以上版本
• 检查显卡驱动是否支持CUDA 11.8
• 验证PyTorch版本与SD框架的兼容性
建议通过命令行输入nvidia-smi查看显卡状态,使用python --version确认Python环境。
模型部署标准化流程
- 文件路径规划
不同模型类型需放置于特定目录:
├── models
│ ├── Stable-diffusion(主模型存放处)
│ ├── Lora(风格模型专用)
│ ├── embeddings(文本嵌入模型)
│ └── VAE(视觉解码器)
Windows用户路径示例:C:\SD-webui\models\Stable-diffusion
Linux/Mac用户路径示例:~/stable-diffusion-webui/models/Lora

- 模型激活步骤
(1)将下载的模型文件放置对应目录
(2)重启SD WebUI界面
(3)在模型选择下拉菜单定位目标模型
(4)检查控制台日志是否显示"Loaded model"提示
进阶配置技巧
多模型协同工作
通过语法<lora:模型名称:权重值>实现多模型叠加,推荐权重范围0.5-1.2,例如输入portrait of a woman <lora:animeStyle_v2:0.8>可融合人像与动漫风格。性能优化方案
• 启用--xformers参数提升生成速度
• 使用--medvram参数优化显存占用
• 设置--precision full确保高质量输出
故障排查指南
模型加载失败
(1)检查文件完整性:对比官方提供的MD5校验值
(2)验证模型类型与目录匹配性
(3)查看错误日志中的CUDA版本冲突提示生成结果异常
(1)确认VAE文件是否缺失
(2)测试不同采样器(如Euler a/DPM++ 2M)
(3)调整CFG Scale值(建议7-12区间)显存不足报错
(1)降低生成分辨率至512x768
(2)添加--lowvram启动参数
(3)升级显卡驱动至最新版本
模型安全规范
- 来源验证:仅从HuggingFace、CivitAI等可信平台获取模型
- 数字签名:优先选择带有创作者认证标识的模型文件
- 沙盒测试:新模型首次使用建议在隔离环境运行
从实际操作经验来看,模型部署的成功率与文件管理的规范性直接相关,建议建立模型分类标注系统,例如使用[作者][类型][版本号]的命名规则,对于需要频繁切换模型的创作者,可安装模型快速切换插件实现效率提升,当前社区正在推动模型标准化进程,未来或出现统一的模型应用商店,这将大幅降低技术使用门槛。
最后需要提醒的是,模型使用应严格遵守知识产权法规,部分商用模型需要额外授权,创作者在下载前务必仔细阅读许可协议,随着SD生态的持续发展,掌握模型部署技能将成为数字内容创作的核心竞争力之一。

 13888888888
13888888888

 点击咨询
点击咨询 