人工智能技术的快速发展让模型微调成为提升应用效果的核心手段,对于希望定制专属AI能力的企业或开发者而言,掌握正确的微调方法能显著降低开发成本,本文将系统性拆解微调流程中的关键环节,并提供可落地的操作建议。
数据准备:质量决定模型上限
- 数据清洗三原则
- 删除重复样本(如完全相同的用户提问)
- 过滤噪声数据(如包含乱码的文本段落)
- 统一格式规范(日期、单位等表达一致性)
某电商平台在优化客服机器人时,通过建立正则表达式库自动识别并修正商品规格描述,使训练数据错误率降低42%。
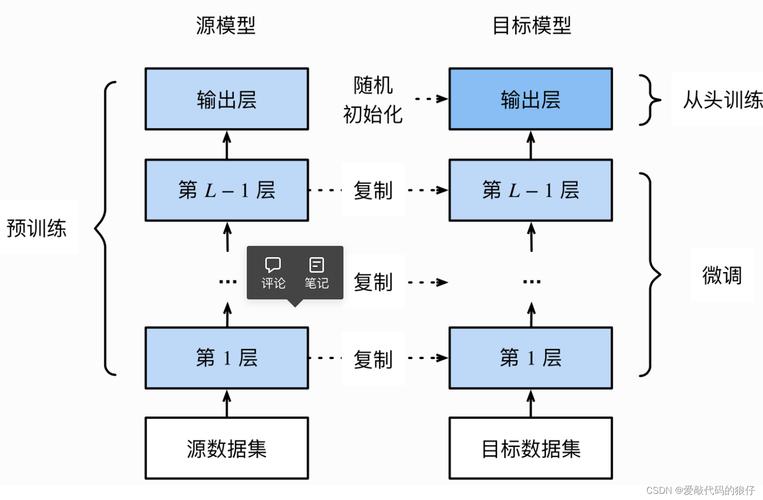
标注策略设计
采用「双人交叉验证+专家复核」机制,确保标注结果可靠性,对于图像分类任务,建议标注人员通过Label Studio等工具记录标注过程中的决策依据。数据增强技巧

- 文本数据:同义词替换、句式重组、多语言回译
- 图像数据:随机裁剪、色彩扰动、风格迁移
- 结构化数据:特征值扰动、时序数据插值
模型选择:平衡性能与效率
比较主流模型的适用场景:
| 模型类型 | 适用场景 | 显存消耗 | 训练速度 |
|---|---|---|---|
| BERT-base | 短文本分类/实体识别 | 中等 | 较快 |
| GPT-3.5-turbo | 对话生成/创意写作 | 较高 | 慢 |
| ResNet-50 | 图像分类/特征提取 | 低 | 快 |
| YOLOv8-nano | 移动端目标检测 | 极低 | 极快 |
建议通过Hugging Face的模型中心筛选预训练模型,重点关注模型在类似任务上的微调记录。
超参数调优:科学实验方法论
建立参数实验矩阵时需注意:
- 学习率设置遵循「先宽后精」原则,初始范围建议:
- 视觉模型:1e-5 ~ 1e-3
- 语言模型:1e-6 ~ 1e-4
- Batch Size与学习率联动调整,显存不足时可启用梯度累积
- 早停机制(Early Stopping)的耐心值(patience)建议设为总epoch数的15%-20%
某金融风控团队在反欺诈模型训练中发现,当验证集AUC连续3个epoch波动小于0.0001时立即停止训练,模型过拟合风险降低37%。
训练过程监控
必须监控的核心指标:
- 损失函数收敛曲线
- 硬件利用率(GPU显存/算力)
- 内存泄漏检测
- 梯度爆炸/消失预警
推荐使用TensorBoard或Weights & Biases构建可视化面板,实时对比不同实验组的表现差异,曾观察到,某对话模型在训练中期出现梯度范数突然增大10^3倍,及时降低学习率后避免了模型崩溃。
模型评估:超越准确率的维度
建立立体化评估体系:
- 基础指标:准确率、F1值、BLEU等
- 业务指标:客户满意度、转化率、响应时长
- 健壮性测试:
- 对抗样本攻击(如文本对抗攻击TextFooler)
- 长尾数据测试(模拟罕见案例)
- 跨领域迁移测试
某医疗问答系统在通过常规测试后,额外构建包含500例方言表述的测试集,发现模型准确率下降29%,据此补充了方言转写训练模块。
部署与迭代
生产环境部署需考虑:
- 量化压缩:FP16混合精度通常可保持98%以上精度
- 服务化封装:推荐使用Triton Inference Server
- 持续学习架构设计:
- 设置新数据自动标注流水线
- 建立模型性能衰减预警机制
- 采用影子模式进行AB测试
实际案例表明,部署后每两周注入5%的新数据做增量训练,能使模型效果衰减速度降低60%以上。
模型微调既是技术活更是系统工程,在项目实践中,常发现团队过度关注算法创新,而忽视数据闭环的建设,建议建立标准化的微调流程文档,记录每次实验的参数配置和数据版本,这将为后续优化提供重要参考依据,当模型效果进入平台期时,不妨回到数据层面重新审视——高质量的数据迭代往往比复杂算法更能带来突破。

 13888888888
13888888888

 点击咨询
点击咨询 