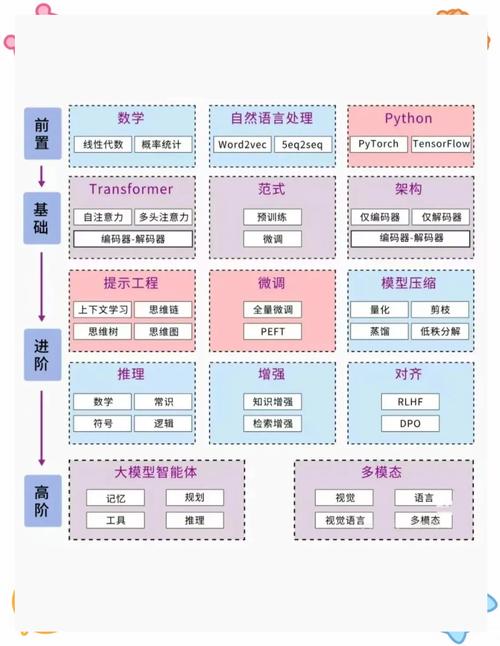
在人工智能技术快速迭代的今天,模型合并已成为提升算法性能、优化资源利用的重要手段,无论是开发者希望整合不同模型的优势,还是企业需要降低计算成本,合并AI模型都能提供高效解决方案,本文将系统讲解模型合并的核心逻辑、主流方法及实际应用中的注意事项,帮助读者快速掌握这一技术。
模型合并的核心逻辑与价值
模型合并的本质是通过特定策略将多个独立训练的模型整合为一个更强大的统一模型,其核心价值体现在三个方面:
- 性能增强:不同模型可能擅长处理特定类型的数据,合并后能综合各模型的优势。
- 资源优化:单个模型推理比多个模型并行运行更节省内存与算力。
- 泛化能力提升:合并过程本质是对不同模型知识进行蒸馏,可减少过拟合风险。
在图像识别任务中,一个模型可能擅长识别纹理细节,另一个模型对形状特征敏感,合并后的模型可在保持较小体积的同时,显著提升识别准确率。
主流模型合并方法详解
方法1:权重平均法(Weight Averaging)
操作步骤:

- 训练多个结构相同的模型(如不同初始化参数或数据增强版本)
- 对各模型对应层的权重取算术平均或加权平均
- 验证合并后模型性能
适用场景:
- 同架构模型集成
- 对抗训练震荡问题
- 提升模型稳定性
典型案例:
在自然语言处理领域,BERT模型的不同训练轮次权重进行平均后,文本分类准确率可提升0.5%-1.2%。
方法2:特征层融合(Feature Fusion)
实施流程:
- 选取两个及以上异构模型(如CNN+Transformer)
- 在中间特征层建立连接通道
- 设计融合机制(拼接/加权/注意力机制)
- 微调连接层参数
技术要点:
- 需确保特征维度兼容
- 建议从浅层到深层逐步融合
- 采用残差连接避免信息丢失
某医疗影像分析项目通过融合ResNet50的特征图与Vision Transformer的全局注意力特征,将肿瘤检测F1分数从89.3%提升至92.7%。
方法3:知识蒸馏法(Knowledge Distillation)
创新实践:
- 教师模型(复杂模型)生成软标签(Soft Targets)
- 学生模型(轻量模型)学习软标签分布
- 引入温度系数控制知识传递强度
进阶技巧:
- 多教师协同蒸馏:融合3-5个教师模型的输出
- 分层蒸馏:逐层传递不同粒度的知识
- 动态权重分配:根据样本难度调整教师权重
某手机端语音识别系统通过蒸馏合并三个专业模型,在保持10ms延迟的同时,将错误率从15%降至11%。
实施过程中的关键注意事项
模型兼容性验证
- 架构对齐:检查输入输出维度、激活函数类型
- 数据一致性:确保训练数据分布相近
- 量化校准:合并前统一模型精度(FP32/FP16)
性能评估策略
- 建立多维评估体系:准确率/推理速度/内存占用
- 设计对抗测试集:包含边缘案例和噪声数据
- 监控模型退化:设置早停机制(Early Stopping)
资源管理方案
- 内存优化:采用梯度检查点技术
- 计算加速:使用TensorRT等推理优化框架
- 硬件适配:针对CPU/GPU/NPU调整合并策略
典型应用场景分析
场景1:多模态任务增强
将视觉模型与语言模型合并,构建可同时处理图像和文本的跨模态系统,某电商平台通过合并商品图像识别模型与评论情感分析模型,实现「看图评物」功能,用户转化率提升23%。
场景2:边缘设备部署
合并后的轻量化模型更适合物联网设备,某工业质检系统通过合并三个检测模型,在保持99.1%检出率的同时,将模型体积从850MB压缩至120MB。
场景3:持续学习系统
通过增量式模型合并实现知识积累,某金融风控平台每月合并新训练模型,使欺诈检测准确率保持年均5%的持续增长。

 13888888888
13888888888

 点击咨询
点击咨询 